
Distance Vector 알고리즘
각 이웃들에서 목적지까지 최소비용 추정치를
행렬형태로 전달해주기 때문에
거리벡터이다.
(벡터 = 한줄행렬)
벨만포드 방정식 (동적 프로그래밍)

- : 노드 x에서 이웃 v로 가는 비용
- : 이웃 v에서 목적지 로 가는 최소 비용 경로
- min 연산은 x의 모든 이웃 v에 대해 적용됩니다.
이웃한 링크의 cost만 알고 있는 상황이므로
c()만 알고, d()는 알 수 없다
d()는 어떻게 알아낼까?
ㅡ> 재귀적으로 c()를 계속 이용해서 구한다.
벨만포드 방정식 예시

Distance Vector 알고리즘

- Dx ( Distance Vector )
- 출발지 : x
- 목적지 : N에 있는 모든 노드
- 각 노드까지의 최소거리 추정치를 모은 벡터
- ex) Dx = [ Dx(y), Dx(z), ... ]
- Dx(y)
- 노드 x에서 노드 y로 가는 최소 비용의 추정치를 의미
- y는 N에 있는 노드 중 하나
- 벨만포드 방정식 사용해서 최소 비용 추정
- 노드 x는 Dx를 갱신하고 관리하며, 이는 모든 노드 y에 대한 최소 비용 추정치를 포함하는 벡터입니다.
- 여기서 N은 네트워크의 모든 노드 집합을 나타냅니다.
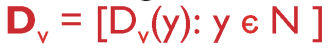
- 노드 x는 자신과 이웃 노드 v 간의 연결 비용 c(x,v)를 알고 있습니다.

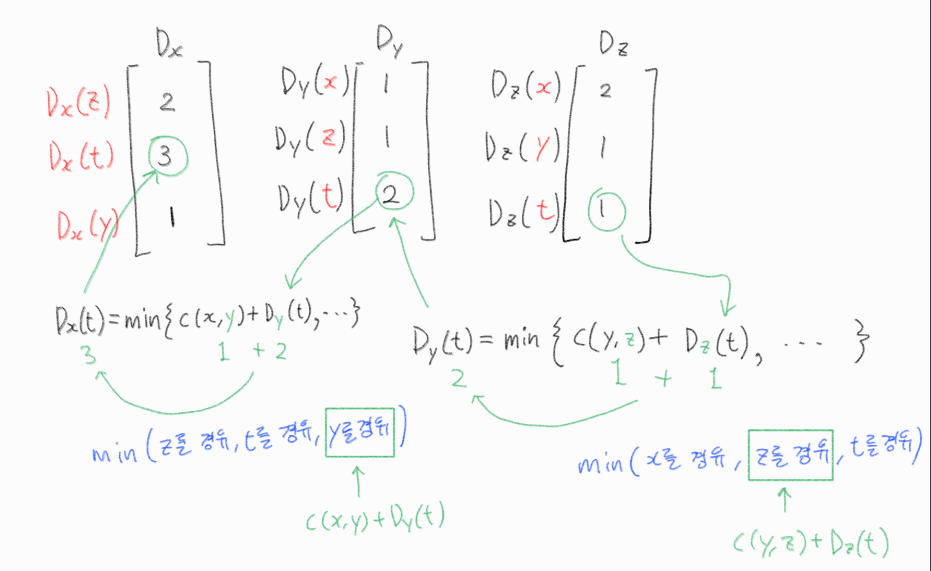
즉, 노드x는 Dx 벡터를 관리하는데
이웃으로부터 Dv 벡터를 주기적으로 전달받아서, v를 경유하는 벨만포드 방정식 값을 갱신하며 Dx를 관리하는 것이다.
여러번 갱신하면 실제 최소비용으로 수렴하게 된다.
key idea
- 주기적인 정보 교환: 각 노드는 주기적으로 자신의 거리 벡터를 이웃 노드에게 전송합니다. 이웃 노드로부터 새로운 거리 벡터 정보를 받으면 이를 바탕으로 자신의 거리 벡터를 갱신합니다.
- Bellman-Ford 방정식 적용: 노드 x가 이웃 노드 v로부터 새로운 거리 벡터 정보를 받으면, Bellman-Ford 방정식을 사용하여 자신의 거리 벡터 Dx(y)를 업데이트합니다. 이 방정식은 아래와 같습니다:

- 여기서 c(x,v)는 노드 와 사이의 비용이고, Dv(y)는 이웃 노드 v로부터 목적지 까지의 최소 비용입니다.
- 수렴: 거리 벡터 알고리즘은 자연스러운 조건 하에서 수렴합니다. 즉, 여러 번의 업데이트 과정을 거치면, 각 노드의 거리 벡터는 실제 최소 비용 경로에 수렴하게 됩니다.
반복, 비동기, 분산
Distance Vector 알고리즘은 반복적이고 비동기적이며 분산된 방식으로 작동합니다.
- 반복적: 각 노드는 지역적으로 변화가 발생할 때마다 알고리즘을 반복적으로 수행합니다.
- 이는 로컬 링크 비용의 변화
- 또는 이웃 노드로부터 DV(거리 벡터) 업데이트 메시지를 수신할 때 발생합니다.
- 비동기적: 모든 노드가 동시에 업데이트할 필요가 없습니다. 노드는 각자의 시간에 따라 독립적으로 작동할 수 있으며, 이 때문에 네트워크 전체가 동시에 변경되지 않아도 됩니다.
- 분산된: 각 노드는 자신의 DV(거리 벡터)가 변경될 때만 이웃에게 알립니다. 이웃 노드도 마찬가지로 DV가 변경되면 다시 그들의 이웃에게 알립니다. 이렇게 네트워크 전체가 분산된 방식으로 정보가 전파됩니다.

각 노드의 작동 방식:
- 대기: 로컬 링크 비용에 변화가 생기거나 이웃으로부터 메시지를 받으면 작동을 시작합니다.
- 재계산: 받은 정보를 바탕으로 새로운 거리 벡터 값을 계산합니다.
- 변경 사항 알림: 계산된 거리 벡터 값에 변화가 생기면, 이웃 노드들에게 그 변경 사항을 알립니다.
예시

- 초기 테이블: 각 노드는 자신이 직접 연결된 이웃에 대한 거리만 알고 있으며, 다른 노드에 대한 경로는 아직 모르는 상태입니다. 초기 값은 이웃 노드와의 직접 연결된 경로 값이고, 연결되지 않은 경로는 무한대로 설정됩니다.
- 갱신 과정: 각 노드는 이웃 노드들로부터 거리 벡터 정보를 받아 자신의 테이블을 업데이트합니다. 예를 들어, 노드 x는 이웃 y와 z로부터 정보를 받아 노드 y로 가는 비용을 계산하며, 직접 연결된 경로와 이웃을 거쳐 가는 경로를 비교하여 최소 비용을 선택합니다.
- 결과 테이블: 최종적으로 모든 노드는 자신이 연결된 경로와 이웃 노드를 거쳐 가는 최소 비용 경로를 알게 되어 테이블을 완성하게 됩니다.
즉, 이 과정에서 각 노드는 Bellman-Ford 방정식을 사용하여 최소 비용 경로를 지속적으로 갱신합니다.
여기서 link cost가 변하면 또 업데이트 한다 (진동)
Count to infinity 문제

x-y 링크가 4에서 50으로 바뀌면
y는 dy(x)에 c(y,z) + dz(x) = 1 + 5 = 6를 선택하게 된다.
근데 이 5는 사실 z에서 y를 거쳐 x로 가는 길이라서
5가 아니라 51이고
y에서 주는 거리벡터에 의존한 값이다.
따라서 dy(x)가 6으로 업데이트 되면
dz(X)는 7로 업데이트 된다.
이렇게 50이 될때까지 +1씩 계속 업데이트 하는 문제가 count to infinity 문제다.
이런문제는, 이웃에게 전달한 최소거리가, 그 이웃을 거치는 경로라서 발생한다.
Count-to-Infinity 해결책:
- Split Horizon: 한 노드가 특정 목적지로의 경로를 다른 노드에게 광고할 때, 자신에게서 그 목적지로 가는 경로는 광고하지 않도록 하는 기법입니다.
- Poison Reverse: Split Horizon의 확장 개념으로, 만약 어떤 노드가 이웃 노드로부터 특정 목적지로 가는 경로를 받았다면, 그 경로가 더 이상 유효하지 않음을 명시적으로 "독(poison)"을 통해 알립니다. 즉, 해당 경로의 비용을 무한대로 설정하여 다시 전파하는 방법입니다.
- Hold-Down Timers: 특정 경로가 불안정할 때, 그 경로에 대한 업데이트를 일정 기간 동안 차단하여 잘못된 정보를 전파하는 것을 방지하는 방법입니다.
z노드의 특정 최소거리가 y를 경유해서 간다면
y에게 거리벡터를 전달할 때 주의한다.
전달하지 않거나, 무한대(Poison)로 전달한다.
PPT 내용 (링크코스트 변화)

- Link Cost 변화: 네트워크 상에서 노드 간 링크의 비용이 변하면 해당 노드는 이를 감지하고 자신이 가진 경로 정보를 갱신해야 합니다.
- DV 업데이트: 비용이 변경되면 노드는 자신이 가진 경로 정보(Distance Vector)를 업데이트하고 이웃 노드들에게 이 변화를 알립니다.
- Good News Travels Fast: 긍정적인 변화(경로 비용 감소 등)는 이웃 노드들에게 빠르게 전파됩니다. 이웃 노드들이 이를 받고 자신들의 경로 정보를 다시 계산하여 다음 이웃에게 전달하는 방식입니다.
단계별 설명:
- t₀: y 노드가 링크 비용 변화를 감지하고, 자신의 Distance Vector를 업데이트합니다. 그리고 이 변화를 이웃 노드들(여기서는 z 노드)에게 알립니다.
- t₁: z 노드가 y로부터 업데이트된 정보를 받습니다. z는 y를 통해 x로 가는 최소 비용을 다시 계산하고, 업데이트된 Distance Vector를 자신의 이웃에게 다시 보냅니다.
- t₂: y가 z로부터 업데이트된 정보를 받습니다. 하지만, y의 경로 정보는 더 이상 변화하지 않기 때문에 z에게 다시 메시지를 보내지 않습니다.
이러한 방식으로 link cost 변화는 네트워크를 통해 빠르게 전달되고, 각 노드들은 지속적으로 자신들의 경로 정보를 최신 상태로 유지할 수 있게 됩니다.

1. Bad News Travels Slow (나쁜 소식은 느리게 전파됨):
- 링크 비용이 증가할 때, 그 정보는 네트워크를 통해 느리게 전파되는 경향이 있습니다.
- Count to Infinity 문제는 이와 관련이 있습니다. 이는 링크가 끊어지거나 비용이 매우 높아졌을 때, 라우터들이 비용을 무한대로 업데이트하기까지 시간이 오래 걸리는 문제를 의미합니다.
- 예시에서 X와 Y 사이의 링크 비용이 60으로 변할 때, 그 영향이 느리게 전파되면서 네트워크가 안정화되기까지 44번의 업데이트가 필요합니다.
2. Poisoned Reverse (독이 든 역방향):
- 이 문제를 해결하기 위한 한 가지 방법은 Poisoned Reverse라는 전략입니다.
- 이 방법은 Z가 Y를 통해 X에 접근하고 있을 때, Z가 Y에게 "X로 가는 내 경로는 무한대야"라고 알림으로써 Y가 Z를 경유해 X로 가는 경로를 선택하지 않도록 하는 방식입니다.
- Poisoned Reverse는 Count to Infinity 문제를 완전히 해결하지는 못하지만, 특정한 상황에서는 경로 루프를 방지하는 데 도움이 됩니다.
Count to Infinity 문제는 DV 알고리즘의 주요한 단점 중 하나이며, 다양한 방식으로 이 문제를 줄이려는 시도가 이루어졌습니다. Poisoned Reverse는 그 중 하나의 예입니다.
[Link State] VS [Distance Vector]
1. Message Complexity (메시지 복잡도)
- LS (Link State):
- 각 노드가 전체 네트워크 토폴로지를 알기 위해서는 네트워크의 모든 링크 상태를 알아야 합니다. 따라서 O(nE) 메시지가 전송됩니다. 여기서 n은 노드의 개수, E는 링크의 개수입니다.
- DV (Distance Vector):
- 인접한 이웃 간에만 메시지가 교환되며, 수렴 시간은 상황에 따라 달라집니다. 그러나 LS에 비해 메시지의 양은 적습니다.
2. Speed of Convergence (수렴 속도)
- LS:
- 수렴 속도는 O(n^2)로 알려져 있으며, 네트워크 상태에 따라 O(nE)메시지가 필요할 수 있습니다. 수렴하는 동안 진동(oscillation)이 발생할 수도 있습니다.
- DV:
- 수렴 시간은 상황에 따라 달라지며, 특히 경로 루프가 생길 수 있고 Count-to-Infinity 문제로 인해 수렴이 느려질 수 있습니다.
3. Robustness (견고성)
- LS:
- 라우터가 오작동할 경우, 잘못된 링크 비용을 광고할 수 있지만, 각 노드는 자신의 테이블을 계산하기 때문에 오류가 네트워크에 쉽게 퍼지지 않습니다.
- DV:
- DV 라우터가 잘못된 경로 비용을 광고할 수 있으며, 각 노드의 테이블이 다른 노드에 의해 사용되므로 오류가 네트워크 전체에 퍼질 수 있습니다.
이를 통해 LS 알고리즘은 메시지 복잡도가 높지만 더 견고하고 예측 가능하며, DV 알고리즘은 메시지 복잡도가 낮지만 오류가 발생할 경우 네트워크에 더 큰 영향을 미칠 수 있음을 알 수 있습니다.
'CS > 네트워크' 카테고리의 다른 글
| 링크 계층1 - 서론, MAC 프로토콜, CSMA/CD (0) | 2024.10.15 |
|---|---|
| 네트워크계층6 (1) | 2024.10.10 |
| 네트워크계층4 - (1) | 2024.10.08 |
| 네트워크계층3 - NAT, DHCP, datagram, 단편화/재조립 (0) | 2024.10.05 |
| 네트워크계층1 (0) | 2024.10.01 |