
-
라우터가 하는 일
-
IP datagram format
-
IP Address (IPv4)
-
Grouping Related Hosts
-
계층적 주소 지정
-
(P) 확장성 문제 (Scalability Challenge)
-
(S) 계층적 주소 지정 : IP Prefixes
-
Subnet Mast
-
확장성 개선
-
호스트 추가의 용이함
-
계층적 주소 할당
-
Classful Addressing VS CIDR
-
Classful Addressing
-
Classless Inter-Domain Routing (CIDR)
-
CIDR 패킷 포워딩의 문제
-
(S) Longest Prefix Match Forwarding
-
Subnets
-
Network Address Translatino (NAT)
■ 프로토콜
ㅡ> app 계층 : HTTP
ㅡ> transport 계층 : TCP, UDP
ㅡ> network 계층 : IP
■ 라우터가 하는 일
1. 포워딩
2. 라우팅
라우터가 하는 일

포워딩
ㅡ> 패킷 해더에 목적지를 읽음
ㅡ> 포워딩 테이블에서 그 목적지를 찾고 보냄
라우팅
ㅡ> 포워딩 테이블을 만드는 것
ㅡ> 라우팅 알고리즘 사용
포워딩 테이블은 범위로 되어있음
이것도 맞고 저것도 맞으면 가장 길게 매칭되는 것을 사용
우체국에서 쓰는것과 같음
IP datagram format

ver : IP 프로토콜 버전
length : 패킷의 전체 길이
Source IP : 송신자 IP 주소
Destination IP : 목적지 IP 주소
TTL (time to live) : 초기값을 설정하고, 라우터를 거칠때마다 값이 1씩 감소. 0이되면 패킷 버림. 네트워크 안에서 무한루프 도는 것을 방지하기 위함.
upper layer : 상위계층 프로토콜이 무엇인지 (TCP or UDP)
인터넷에서 상당수의 패킷들이 40바이트짜리다.
그건 TCP ack다.
data없이 IP헤더(20btyes)와 TCP헤더(20bytes)라서 그렇다.
- IP 프로토콜 버전 번호 (ver): IP 프로토콜의 버전 (예: IPv4, IPv6).
- 헤더 길이 (header length): IP 헤더의 길이를 바이트 단위로 나타냅니다.
- 서비스 유형 (type of service): 패킷이 어떻게 처리될지 정의하는 필드.
- 데이터그램의 전체 길이 (total datagram length): 전체 IP 패킷의 크기.
- 식별자 (identifier), 플래그 (flags), 오프셋 (fragment offset): 패킷 단편화 및 재조립에 사용됩니다.
- TTL (time to live): 패킷이 네트워크를 통과할 수 있는 최대 홉 수.
- 상위 계층 프로토콜 (upper layer protocol): 데이터를 처리할 상위 프로토콜 (예: TCP, UDP).
- 헤더 체크섬 (header checksum): IP 헤더의 오류를 확인하는 필드.
- 출발지 및 목적지 IP 주소: 패킷의 출발지 및 목적지 주소.
- 옵션 필드: 패킷의 경로 추적 등의 추가 정보를 포함할 수 있는 필드.
- 데이터 필드: TCP/UDP 세그먼트나 애플리케이션 데이터를 포함합니다.
오버헤드 부분에서는 IP와 TCP 헤더 각각이 20 바이트씩 차지하여, 총 40 바이트의 오버헤드가 발생한다고 설명하고 있습니다.
IP Address (IPv4)

IP 주소
ㅡ> 32비트로 구성된 고유한 숫자
ㅡ> 8비트씩 끊어서 10진수로 표기함 (4개로 분할, 0~255)
ㅡ> 인터페이스(호스트 또는 라우터 등)를 식별하는 데 사용
인터페이스 : 호스트 안에 있는 네트워크 인터페이스 (NIC) (LAN카드, WIFI 어댑터 등..)
컴퓨터에 네트워크 인터페이스 여러개 꼽으면, ip주소도 여러개다.
대표적으로 라우터가 그렇다.
Grouping Related Hosts

- LAN: 호스트들이 동일한 지역 내에서 연결된 네트워크입니다. LAN은 보통 학교, 회사 또는 가정 내의 네트워크를 의미합니다.
- WAN: LAN과 같은 지역 네트워크들을 서로 연결하는 보다 큰 범위의 네트워크입니다. WAN은 주로 라우터(router)를 통해 LAN들을 연결하여 더 넓은 네트워크를 구성합니다
ex)
LAN1 = 한양대 네트워크
LAN2 = 중앙대 네트워크
■ 인터넷
ㅡ> Inter + Network
ㅡ> 개별 호스트가 아니라 네트워크 자체를 연결함
ㅡ> LAN과 WAN이 모여서 형성된 전 세계적인 네트워크
계층적 주소 지정
(P) 확장성 문제 (Scalability Challenge)

(P)
만약 네트워크에 있는 각 호스트가 임의의 주소를 가지고 있다면
ㅡ> 모든 라우터는 각 호스트로 데이터를 전송하기 위해 모든 호스트의 주소를 알고 있어야 합니다.
ㅡ> 이렇게 되면, 각 라우터의 포워딩 테이블에 저장해야 하는 정보가 매우 많아져서 관리가 어렵고, 네트워크가 확장될수록 성능 저하가 발생할 수 있습니다.
(S)
이 문제를 해결하기 위해 주소 체계나 라우팅 알고리즘에서 계층적 구조를 사용하여, 라우터가 모든 호스트의 세부 정보를 알 필요 없이 네트워크의 일부 정보만 가지고도 효과적으로 라우팅을 할 수 있도록 설계하는 것이 필요합니다.
(S) 계층적 주소 지정 : IP Prefixes
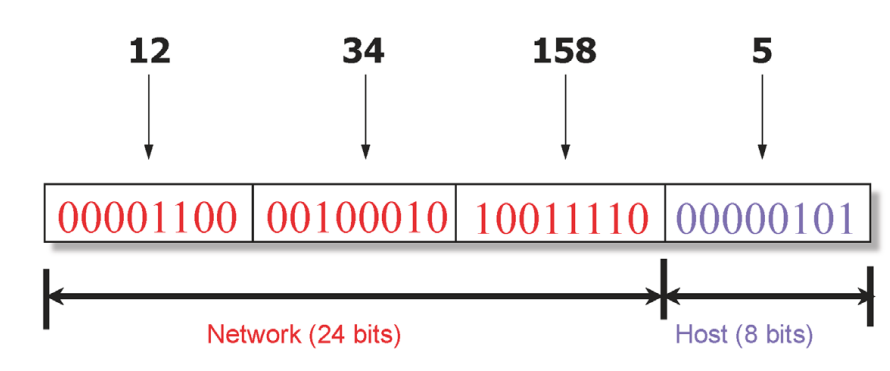
앞부분은 Network ID
뒷부분은 Host ID
같은 네트워크에 속한 호스트들은 앞부분이 같음
12.34.158/24
/24 : 24비트까지 네트워크id라는 뜻
Subnet Mast

IP주소에 서브넷mask를 따라다니게 해서
어디까지가 네트워크 id인지 구분하게 한다.
패킷에는 서브넷 mask가 없다.
라우터 테이블에 서브넷mask가 있다.
확장성 개선

IP Prefixes를 통해, 확장성 문제를 개선했다.
호스트 추가의 용이함
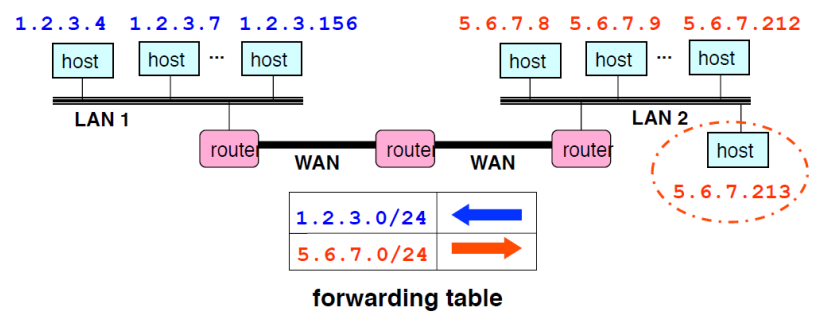
라우터를 업데이트할 필요가 없음
ㅡ> 예를 들어, 5.6.7.213이라는 새로운 호스트를 오른쪽 네트워크(LAN 2)에 추가
ㅡ> 포워딩 테이블을 새롭게 추가할 필요가 없음
ㅡ> 이미 5.6.7.0/24 서브넷에 대한 경로 정보가 포워딩 테이블에 기록되어 있기 때문
계층적 주소 할당

- 계층적 구조: 대규모 네트워크 블록(예: 12.0.0.0/8)이 할당되고, 그 안에서 더 작은 서브넷 블록(예: 12.1.0.0/16, 12.2.0.0/16 등)이 할당됩니다. 이와 같이, 서브넷 블록들은 점점 더 작은 프리픽스로 나뉘어, 특정 네트워크 범위를 정의합니다.
- 예시: 12.0.0.0/8 네트워크 블록이 있고, 그 안에서 /16 서브넷 블록으로 나뉩니다. 이 중 일부는 /24나 /19처럼 더 세분화된 블록을 가질 수 있습니다.
Classful Addressing VS CIDR
Classful Addressing

■ Classful Addressing
ㅡ> 과거에 사용되던 고정된 크기의 주소 할당 방식
ㅡ> 각 클래스는 네트워크의 크기에 따라 달라지며, 그 구분은 IP 주소의 첫 몇 비트에 의해 결정
- Class A: 0으로 시작, 매우 큰 네트워크에 할당됨 (/8 블록, 예: MIT의 18.0.0.0/8)
- Class B: 10으로 시작, 큰 네트워크에 할당됨 (/16 블록, 예: Princeton의 128.112.0.0/16)
- Class C: 110으로 시작, 작은 네트워크에 할당됨 (/24 블록, 예: AT&T Labs의 192.20.225.0/24)
- Class D: 1110으로 시작, 멀티캐스트 그룹을 위한 예약
- Class E: 11110으로 시작, 미래 사용을 위해 예약됨
Classless Inter-Domain Routing (CIDR)

클래스가 고정되지 않고, 서브넷mask로 네트워크id 범위를 지정한다.
ex) 위 그림
서브넷mask가 15비트까지 네트워크 id임을 알려준다.
class adrressing으로 네트워크id 크기 정할땐
쓸데없이 호스트id 크기가 크거나 부족해서 포워딩 테이블 크기 커지고 그랬는데
CIDR로 바뀌고 유연성있어졌다
CIDR 패킷 포워딩의 문제

(P) 포워딩 테이블에 여러 일치 항목이 생길 수 있다
- 예를 들어, 201.10.0.0/21과 201.10.6.0/23이라는 두 개의 항목이 포워딩 테이블에 존재할 수 있습니다.
- 201.10.6.17이라는 IP 주소는 이 두 네트워크 프리픽스에 모두 일치합니다. 이는 어떤 경로를 선택할지 모호하게 만들 수 있습니다.
(클래스 주소의 경우, 앞의 비트가 구분되어 있어서 겹치지 않는 듯)
(S) Longest Prefix Match Forwarding
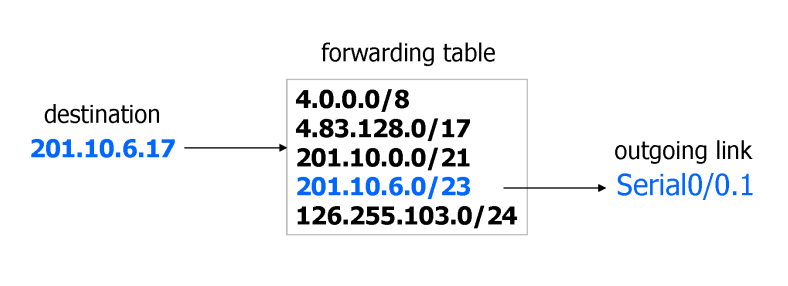
라우터는 가장 긴 prefix를 기준으로 경로를 찾습니다.
예를 들어, 목적지 주소가 201.10.6.17인 경우, 포워딩 테이블에서 가장 긴 prefix가 201.10.6.0/23이므로 이 경로를 선택하여 포워딩합니다.
Subnets

서브넷
ㅡ> 같은 서브넷id(prefix)를 가진 디바이스 인터페이스의 집합
ㅡ> 라우터를 거치지 않고 접근이 가능한 host들의 집합
(그림) 라우터
ㅡ> 인터페이스 3개, ip 3개
ㅡ> 서브넷 3개의 교집합
ㅡ> 223.1.1.x
ㅡ> 223.1.2.x
ㅡ> 223.1.3.x

(그림)
ㅡ> 서브넷 6개
Network Address Translatino (NAT)
ipv4는 32비트
2^32 = 대략 40억
사람 수보다 부족하니 요즘엔 ip숫자가 부족함
이걸 NAT라는 트릭으로 해결
(부족한걸 근본적으로 해결하는건 아니라서 트릭이라고 하자)
NAT(Network Address Translation)은 IP 주소 부족 문제를 해결하기 위해 도입된 단기적 해결책입니다. 1990년대 초 IPv4 주소가 고갈될 것으로 예상되었고, 이에 따라 IPv6와 같은 대안이 개발되기 시작했지만, NAT는 그 중간 기간 동안 여러 장치들이 하나의 공용 IP 주소를 공유할 수 있게 해주는 방식으로 IPv4 주소 공간을 확장하는 임시적인 방법으로 사용되었습니다. 현재는 NAT가 IPv6보다 훨씬 많이 사용되고 있으며, 장치와 호스트 측에서 변경이 필요하지 않은 이점이 있습니다.

- 내부 네트워크(inside): 예를 들어, IP 주소 10.0.0.1과 10.0.0.2와 같은 사설 IP 주소를 사용하는 장치들이 있습니다. 이 주소들은 인터넷상에서 직접적으로 사용될 수 없기 때문에 글로벌하게 주소를 할당받지 않은 상태입니다.
- NAT의 역할: NAT는 라우터와 같은 장치에서 수행되며, 내부에서 나가는 패킷의 출발지 IP 주소를 재작성하고, 외부에서 들어오는 패킷의 목적지 IP 주소도 다시 재작성합니다. 이를 통해 내부 네트워크의 여러 장치들이 하나의 공용 IP 주소를 사용하여 외부 인터넷에 연결됩니다.
- 나가는 패킷(outbound): NAT는 내부 장치가 외부로 요청을 보낼 때 패킷의 출발지 IP 주소를 NAT 장치의 공용 IP 주소로 바꿔줍니다.
- 들어오는 패킷(inbound): 반대로, 외부에서 응답이 오면 NAT는 목적지 IP 주소를 내부 장치의 사설 IP 주소로 변경하여 해당 장치로 전달합니다.
문제: 사설 IP 주소는 글로벌 인터넷에서 직접적으로 접근할 수 없다는 점입니다. NAT는 이러한 문제를 해결해주며, 이를 통해 여러 장치가 동시에 공용 IP 주소를 공유할 수 있게 됩니다.

NAT(Network Address Translation)은 내부 네트워크에서 사용하는 사설 IP 주소를 외부 네트워크와 통신할 때 공인 IP 주소로 변환하는 기술입니다. 이 방식은 내부 네트워크에서 나가는 모든 데이터그램이 동일한 공인 IP 주소(위 그림에서는 138.76.29.7)를 사용하지만 각기 다른 소스 포트 번호를 사용하여 여러 내부 장치의 통신을 구분합니다. 내부 네트워크에서는 각 장치가 사설 IP(10.0.0.x)를 사용하여 통신합니다.
이 방식의 장점은 여러 장치가 하나의 공인 IP 주소를 공유하여 외부와 통신할 수 있다는 점입니다.

모든 호스트가 같은 IP를 사용하면
어떤 호스트의 데이터그램인지 어떻게 알까?
라우터에서 NAT테이블을 사용해서 포트번호로 호스트를 구분한다.
내부 호스트에서 동일한 포트번호를 사용할 수도 있으니, 외부로 보낼때 포트번호를 바꾸고 테이블에 기록해둔다.
'CS > 네트워크' 카테고리의 다른 글
| 네트워크계층4 - (1) | 2024.10.08 |
|---|---|
| 네트워크계층3 - NAT, DHCP, datagram, 단편화/재조립 (0) | 2024.10.05 |
| 전송계층4 - 혼잡 제어, 공정성 (0) | 2024.09.27 |
| 전송계층3 - TCP Flow Control, Conection (3-way handshake) (0) | 2024.09.26 |
| 전송계층2 - TCP, segment구조, RTT, 타임아웃 (0) | 2024.09.20 |
■ 프로토콜
ㅡ> app 계층 : HTTP
ㅡ> transport 계층 : TCP, UDP
ㅡ> network 계층 : IP
■ 라우터가 하는 일
1. 포워딩
2. 라우팅
라우터가 하는 일
포워딩
ㅡ> 패킷 해더에 목적지를 읽음
ㅡ> 포워딩 테이블에서 그 목적지를 찾고 보냄
라우팅
ㅡ> 포워딩 테이블을 만드는 것
ㅡ> 라우팅 알고리즘 사용
포워딩 테이블은 범위로 되어있음
이것도 맞고 저것도 맞으면 가장 길게 매칭되는 것을 사용
우체국에서 쓰는것과 같음
IP datagram format
ver : IP 프로토콜 버전
length : 패킷의 전체 길이
Source IP : 송신자 IP 주소
Destination IP : 목적지 IP 주소
TTL (time to live) : 초기값을 설정하고, 라우터를 거칠때마다 값이 1씩 감소. 0이되면 패킷 버림. 네트워크 안에서 무한루프 도는 것을 방지하기 위함.
upper layer : 상위계층 프로토콜이 무엇인지 (TCP or UDP)
인터넷에서 상당수의 패킷들이 40바이트짜리다.
그건 TCP ack다.
data없이 IP헤더(20btyes)와 TCP헤더(20bytes)라서 그렇다.
- IP 프로토콜 버전 번호 (ver): IP 프로토콜의 버전 (예: IPv4, IPv6).
- 헤더 길이 (header length): IP 헤더의 길이를 바이트 단위로 나타냅니다.
- 서비스 유형 (type of service): 패킷이 어떻게 처리될지 정의하는 필드.
- 데이터그램의 전체 길이 (total datagram length): 전체 IP 패킷의 크기.
- 식별자 (identifier), 플래그 (flags), 오프셋 (fragment offset): 패킷 단편화 및 재조립에 사용됩니다.
- TTL (time to live): 패킷이 네트워크를 통과할 수 있는 최대 홉 수.
- 상위 계층 프로토콜 (upper layer protocol): 데이터를 처리할 상위 프로토콜 (예: TCP, UDP).
- 헤더 체크섬 (header checksum): IP 헤더의 오류를 확인하는 필드.
- 출발지 및 목적지 IP 주소: 패킷의 출발지 및 목적지 주소.
- 옵션 필드: 패킷의 경로 추적 등의 추가 정보를 포함할 수 있는 필드.
- 데이터 필드: TCP/UDP 세그먼트나 애플리케이션 데이터를 포함합니다.
오버헤드 부분에서는 IP와 TCP 헤더 각각이 20 바이트씩 차지하여, 총 40 바이트의 오버헤드가 발생한다고 설명하고 있습니다.
IP Address (IPv4)
IP 주소
ㅡ> 32비트로 구성된 고유한 숫자
ㅡ> 8비트씩 끊어서 10진수로 표기함 (4개로 분할, 0~255)
ㅡ> 인터페이스(호스트 또는 라우터 등)를 식별하는 데 사용
인터페이스 : 호스트 안에 있는 네트워크 인터페이스 (NIC) (LAN카드, WIFI 어댑터 등..)
컴퓨터에 네트워크 인터페이스 여러개 꼽으면, ip주소도 여러개다.
대표적으로 라우터가 그렇다.
Grouping Related Hosts
- LAN: 호스트들이 동일한 지역 내에서 연결된 네트워크입니다. LAN은 보통 학교, 회사 또는 가정 내의 네트워크를 의미합니다.
- WAN: LAN과 같은 지역 네트워크들을 서로 연결하는 보다 큰 범위의 네트워크입니다. WAN은 주로 라우터(router)를 통해 LAN들을 연결하여 더 넓은 네트워크를 구성합니다
ex)
LAN1 = 한양대 네트워크
LAN2 = 중앙대 네트워크
■ 인터넷
ㅡ> Inter + Network
ㅡ> 개별 호스트가 아니라 네트워크 자체를 연결함
ㅡ> LAN과 WAN이 모여서 형성된 전 세계적인 네트워크
계층적 주소 지정
(P) 확장성 문제 (Scalability Challenge)
(P)
만약 네트워크에 있는 각 호스트가 임의의 주소를 가지고 있다면
ㅡ> 모든 라우터는 각 호스트로 데이터를 전송하기 위해 모든 호스트의 주소를 알고 있어야 합니다.
ㅡ> 이렇게 되면, 각 라우터의 포워딩 테이블에 저장해야 하는 정보가 매우 많아져서 관리가 어렵고, 네트워크가 확장될수록 성능 저하가 발생할 수 있습니다.
(S)
이 문제를 해결하기 위해 주소 체계나 라우팅 알고리즘에서 계층적 구조를 사용하여, 라우터가 모든 호스트의 세부 정보를 알 필요 없이 네트워크의 일부 정보만 가지고도 효과적으로 라우팅을 할 수 있도록 설계하는 것이 필요합니다.
(S) 계층적 주소 지정 : IP Prefixes
앞부분은 Network ID
뒷부분은 Host ID
같은 네트워크에 속한 호스트들은 앞부분이 같음
12.34.158/24
/24 : 24비트까지 네트워크id라는 뜻
Subnet Mast
IP주소에 서브넷mask를 따라다니게 해서
어디까지가 네트워크 id인지 구분하게 한다.
패킷에는 서브넷 mask가 없다.
라우터 테이블에 서브넷mask가 있다.
확장성 개선
IP Prefixes를 통해, 확장성 문제를 개선했다.
호스트 추가의 용이함
라우터를 업데이트할 필요가 없음
ㅡ> 예를 들어, 5.6.7.213이라는 새로운 호스트를 오른쪽 네트워크(LAN 2)에 추가
ㅡ> 포워딩 테이블을 새롭게 추가할 필요가 없음
ㅡ> 이미 5.6.7.0/24 서브넷에 대한 경로 정보가 포워딩 테이블에 기록되어 있기 때문
계층적 주소 할당
- 계층적 구조: 대규모 네트워크 블록(예: 12.0.0.0/8)이 할당되고, 그 안에서 더 작은 서브넷 블록(예: 12.1.0.0/16, 12.2.0.0/16 등)이 할당됩니다. 이와 같이, 서브넷 블록들은 점점 더 작은 프리픽스로 나뉘어, 특정 네트워크 범위를 정의합니다.
- 예시: 12.0.0.0/8 네트워크 블록이 있고, 그 안에서 /16 서브넷 블록으로 나뉩니다. 이 중 일부는 /24나 /19처럼 더 세분화된 블록을 가질 수 있습니다.
Classful Addressing VS CIDR
Classful Addressing
■ Classful Addressing
ㅡ> 과거에 사용되던 고정된 크기의 주소 할당 방식
ㅡ> 각 클래스는 네트워크의 크기에 따라 달라지며, 그 구분은 IP 주소의 첫 몇 비트에 의해 결정
- Class A: 0으로 시작, 매우 큰 네트워크에 할당됨 (/8 블록, 예: MIT의 18.0.0.0/8)
- Class B: 10으로 시작, 큰 네트워크에 할당됨 (/16 블록, 예: Princeton의 128.112.0.0/16)
- Class C: 110으로 시작, 작은 네트워크에 할당됨 (/24 블록, 예: AT&T Labs의 192.20.225.0/24)
- Class D: 1110으로 시작, 멀티캐스트 그룹을 위한 예약
- Class E: 11110으로 시작, 미래 사용을 위해 예약됨
Classless Inter-Domain Routing (CIDR)
클래스가 고정되지 않고, 서브넷mask로 네트워크id 범위를 지정한다.
ex) 위 그림
서브넷mask가 15비트까지 네트워크 id임을 알려준다.
class adrressing으로 네트워크id 크기 정할땐
쓸데없이 호스트id 크기가 크거나 부족해서 포워딩 테이블 크기 커지고 그랬는데
CIDR로 바뀌고 유연성있어졌다
CIDR 패킷 포워딩의 문제
(P) 포워딩 테이블에 여러 일치 항목이 생길 수 있다
- 예를 들어, 201.10.0.0/21과 201.10.6.0/23이라는 두 개의 항목이 포워딩 테이블에 존재할 수 있습니다.
- 201.10.6.17이라는 IP 주소는 이 두 네트워크 프리픽스에 모두 일치합니다. 이는 어떤 경로를 선택할지 모호하게 만들 수 있습니다.
(클래스 주소의 경우, 앞의 비트가 구분되어 있어서 겹치지 않는 듯)
(S) Longest Prefix Match Forwarding
라우터는 가장 긴 prefix를 기준으로 경로를 찾습니다.
예를 들어, 목적지 주소가 201.10.6.17인 경우, 포워딩 테이블에서 가장 긴 prefix가 201.10.6.0/23이므로 이 경로를 선택하여 포워딩합니다.
Subnets
서브넷
ㅡ> 같은 서브넷id(prefix)를 가진 디바이스 인터페이스의 집합
ㅡ> 라우터를 거치지 않고 접근이 가능한 host들의 집합
(그림) 라우터
ㅡ> 인터페이스 3개, ip 3개
ㅡ> 서브넷 3개의 교집합
ㅡ> 223.1.1.x
ㅡ> 223.1.2.x
ㅡ> 223.1.3.x
(그림)
ㅡ> 서브넷 6개
Network Address Translatino (NAT)
ipv4는 32비트
2^32 = 대략 40억
사람 수보다 부족하니 요즘엔 ip숫자가 부족함
이걸 NAT라는 트릭으로 해결
(부족한걸 근본적으로 해결하는건 아니라서 트릭이라고 하자)
NAT(Network Address Translation)은 IP 주소 부족 문제를 해결하기 위해 도입된 단기적 해결책입니다. 1990년대 초 IPv4 주소가 고갈될 것으로 예상되었고, 이에 따라 IPv6와 같은 대안이 개발되기 시작했지만, NAT는 그 중간 기간 동안 여러 장치들이 하나의 공용 IP 주소를 공유할 수 있게 해주는 방식으로 IPv4 주소 공간을 확장하는 임시적인 방법으로 사용되었습니다. 현재는 NAT가 IPv6보다 훨씬 많이 사용되고 있으며, 장치와 호스트 측에서 변경이 필요하지 않은 이점이 있습니다.
- 내부 네트워크(inside): 예를 들어, IP 주소 10.0.0.1과 10.0.0.2와 같은 사설 IP 주소를 사용하는 장치들이 있습니다. 이 주소들은 인터넷상에서 직접적으로 사용될 수 없기 때문에 글로벌하게 주소를 할당받지 않은 상태입니다.
- NAT의 역할: NAT는 라우터와 같은 장치에서 수행되며, 내부에서 나가는 패킷의 출발지 IP 주소를 재작성하고, 외부에서 들어오는 패킷의 목적지 IP 주소도 다시 재작성합니다. 이를 통해 내부 네트워크의 여러 장치들이 하나의 공용 IP 주소를 사용하여 외부 인터넷에 연결됩니다.
- 나가는 패킷(outbound): NAT는 내부 장치가 외부로 요청을 보낼 때 패킷의 출발지 IP 주소를 NAT 장치의 공용 IP 주소로 바꿔줍니다.
- 들어오는 패킷(inbound): 반대로, 외부에서 응답이 오면 NAT는 목적지 IP 주소를 내부 장치의 사설 IP 주소로 변경하여 해당 장치로 전달합니다.
문제: 사설 IP 주소는 글로벌 인터넷에서 직접적으로 접근할 수 없다는 점입니다. NAT는 이러한 문제를 해결해주며, 이를 통해 여러 장치가 동시에 공용 IP 주소를 공유할 수 있게 됩니다.
NAT(Network Address Translation)은 내부 네트워크에서 사용하는 사설 IP 주소를 외부 네트워크와 통신할 때 공인 IP 주소로 변환하는 기술입니다. 이 방식은 내부 네트워크에서 나가는 모든 데이터그램이 동일한 공인 IP 주소(위 그림에서는 138.76.29.7)를 사용하지만 각기 다른 소스 포트 번호를 사용하여 여러 내부 장치의 통신을 구분합니다. 내부 네트워크에서는 각 장치가 사설 IP(10.0.0.x)를 사용하여 통신합니다.
이 방식의 장점은 여러 장치가 하나의 공인 IP 주소를 공유하여 외부와 통신할 수 있다는 점입니다.
모든 호스트가 같은 IP를 사용하면
어떤 호스트의 데이터그램인지 어떻게 알까?
라우터에서 NAT테이블을 사용해서 포트번호로 호스트를 구분한다.
내부 호스트에서 동일한 포트번호를 사용할 수도 있으니, 외부로 보낼때 포트번호를 바꾸고 테이블에 기록해둔다.
'CS > 네트워크' 카테고리의 다른 글
| 네트워크계층4 - (1) | 2024.10.08 |
|---|---|
| 네트워크계층3 - NAT, DHCP, datagram, 단편화/재조립 (0) | 2024.10.05 |
| 전송계층4 - 혼잡 제어, 공정성 (0) | 2024.09.27 |
| 전송계층3 - TCP Flow Control, Conection (3-way handshake) (0) | 2024.09.26 |
| 전송계층2 - TCP, segment구조, RTT, 타임아웃 (0) | 2024.09.20 |