
목차
-
Binary Search Trees
-
Recall: 순서 맵 (Ordered Maps)
-
이진 탐색(Binary Search)
-
탐색 테이블(Search Tables)
-
이진 탐색 트리(Binary Search Trees)
-
검색(Search)
-
삽입(Insertion)
-
삭제(Deletion)
-
(2, 4) Trees
-
다중 검색 트리(Multi-Way Search Tree)
-
(2, 4) 트리의 노드들
-
다중 방향 중위 순회(Multi-Way Inorder Traversal)
-
다중 방향 검색(Multi-Way Searching)
-
(2,4) 트리
-
(2,4) 트리의 높이
-
삽입(Insertion)
-
오버플로우와 분할(Overflow and Split)
-
삽입 분석
Binary Search Trees

Recall: 순서 맵 (Ordered Maps)
- 키는 전체 순서에서 나옴
- 새로운 연산:
- 각각의 연산은 항목에 대한 이터레이터(iterator)를 반환:
- firstEntry(): 맵에서 가장 작은 키
- lastEntry(): 맵에서 가장 큰 키
- floorEntry(k): 인 가장 큰 키
- ceilingEntry(k): 인 가장 작은 키
- 맵이 비어 있으면 모두 end를 반환
- 각각의 연산은 항목에 대한 이터레이터(iterator)를 반환:
이진 탐색(Binary Search)
- 이진 탐색은 키로 정렬된 배열 기반 시퀀스로 구현된 순서 맵에서 get, floorEntry 및 ceilingEntry 연산을 수행할 수 있습니다.
- 높고 낮은 숫자 맞히기 게임과 유사합니다. (high-low game)
- 각 단계마다 후보 항목의 수가 절반으로 줄어듭니다.
- 단계 후에 종료됩니다.
ex) find(7)

탐색 테이블(Search Tables)
- Search Tables은 sorted sequence를 통해 구현된 ordered map입니다.
- 항목들을, 키에 따라 정렬된 array-based sequence에 저장합니다.
- 키를 비교하기 위해 외부 비교자(comparator)를 사용합니다.
- 성능:
- get, floorEntry 및 ceilingEntry 연산은 이진 탐색을 사용하여 O(log n) 시간이 걸립니다.
- insert(삽입) 연산은 최악의 경우 새로운 항목을 위한 공간을 만들기 위해 n개의 항목을 이동해야 하므로 O(n) 시간이 걸립니다.
- erase(삭제) 연산은 최악의 경우 항목을 제거한 후 n개의 항목을 압축해야 하므로 O(n) 시간이 걸립니다.
ㅡ> Binary Search Tree를 쓰자
이진 탐색 트리(Binary Search Trees)
- 이진 탐색 트리는 internal node에 키(또는 키-값 항목)를 저장하는 이진 트리로, 다음 조건을 만족합니다:
- , , 세 노드가 있을 때, 는 의 왼쪽 서브트리에 있고 는 의 오른쪽 서브트리에 있다고 가정합니다.
- 이 경우 입니다.
- External node는 항목을 저장하지 않습니다.
- 이진 탐색 트리의 중위 순회(inorder traversal)는 키를 오름차순으로 방문합니다.

검색(Search)
- 키 를 검색하기 위해, 루트에서 시작하여 아래로 내려가는 경로를 추적합니다.
- 다음에 방문할 노드는 와 현재 노드의 키를 비교한 결과에 따라 결정됩니다.
- 만약 리프(leaf) 노드에 도달하면, 해당 키는 존재하지 않는 것입니다.
- 예시: get(4):
- TreeSearch(4, root) 호출
- floorEntry와 ceilingEntry를 위한 알고리즘도 유사합니다.


삽입(Insertion)
- put(k, o) 연산을 수행하기 위해, 키 를 검색합니다 (TreeSearch 사용).
- 가 트리에 없다고 가정하고, 검색에 의해 도달한 리프 노드를 라고 합시다.
- 우리는 를 노드 에 삽입하고, 를 내부 노드로 확장합니다.
- 예시: 5를 삽입

삭제(Deletion)
- erase(k) 연산을 수행하기 위해, 키 를 검색합니다.
- 키 가 트리에 있다고 가정하고, 를 저장하고 있는 노드를 라고 합시다.
- 만약 노드 가 리프 자식 를 가지고 있다면, 우리는 트리에서 와 를 제거하는 removeExternal(w) 연산을 수행합니다. 이 연산은 와 그 부모를 제거합니다.
- 예시: 4 제거

- 제거할 키 는 두 자식이 모두 내부 노드인 노드 에 저장되어 있습니다.
- 중위 순회(inorder traversal)에서 다음에 오는 내부 노드 를 찾습니다.
- 노드 에 노드 의 키를 복사합니다.
- 노드 와 그 왼쪽 자식 (리프 노드임)를 removeExternal(z) 연산을 통해 제거합니다.
- 예시: 키 3 제거

(2, 4) Trees

다중 검색 트리(Multi-Way Search Tree)
- 다중 검색 트리는 순서가 있는 트리로, 다음과 같은 특성을 가집니다:
- 각 내부 노드는 최소 두 개의 자식을 가지며, 개의 자식을 가진 경우 개의 키-요소 쌍 을 저장합니다.
- 자식 노드 와 키 를 저장하는 노드의 경우:
- 자식 노드 의 서브트리의 키들은 보다 작습니다.
- 자식 노드 의 서브트리의 키들은 와 사이에 있습니다 ( ).
- 자식 노드 의 서브트리의 키들은 보다 큽니다.
- 리프 노드들은 항목을 저장하지 않고 자리 표시자( placeholders )로 사용됩니다

(2, 4) 트리의 노드들
2-노드 (2-node) ➔ 이진 탐색 트리
- 두 개의 자식을 가집니다.
- 하나의 키 을 포함합니다.
- 관례적으로 이고 입니다.
3-노드 (3-node)
- 세 개의 자식을 가집니다.
- 두 개의 키 를 포함합니다.
4-노드 (4-node)
- 네 개의 자식을 가집니다.
- 세 개의 키 를 포함합니다.


다중 방향 중위 순회(Multi-Way Inorder Traversal)
- binary tree에서의 inorder traversal 개념을, 다중 검색 트리(multi-way search tree)로 확장할 수 있습니다.
- 즉, 노드 의 항목 를 방문하는 것은 자식 와 의 서브트리를 재귀적으로 순회하는 중간에 이루어집니다.
- multi-way search tree는 키를 오름차순으로 방문합니다.

다중 방향 검색(Multi-Way Searching)
- binary search tree에서의 검색과 유사합니다.
- 각 내부 노드는 자식 와 키 을 가집니다.
- ( 인 경우): 검색이 성공적으로 종료됩니다.
- : 자식 에서 검색을 계속합니다.
- ( 인 경우): 자식 에서 검색을 계속합니다.
- : 자식 에서 검색을 계속합니다.
- 외부 노드에 도달하면 검색이 실패로 종료됩니다.
예시: 30을 검색

예시 : Search path for key 12 (unsuccessful search)

예시 : Search path for key 24 (successful search)

(2,4) 트리
- (2,4) 트리(2-4 트리 또는 2-3-4 트리라고도 함)는 다음과 같은 특성을 가진 다중 방향 검색 트리입니다:
- 노드 크기 특성(Node-Size Property): 모든 내부 노드는 최대 네 개의 자식을 가집니다.
- 깊이 특성(Depth Property): 모든 외부 노드는 동일한 깊이를 가집니다.
- 자식의 수에 따라 (2,4) 트리의 내부 노드는 2-노드, 3-노드 또는 4-노드라고 불립니다.

(2,4) 트리의 높이
정리(Theorem): 개의 항목을 저장하는 (2,4) 트리는 높이가 입니다.
증명(Proof):
- 를 개의 항목을 가진 (2,4) 트리의 높이라고 합시다.
- 깊이 에서 적어도 개의 항목이 있고, 깊이 에서는 항목이 없기 때문에(외부 노드만 존재), 다음과 같이 됩니다:
- 따라서, 가 됩니다.
- 따라서, 개의 항목을 가진 (2,4) 트리에서의 검색은 시간이 소요됩니다.

삽입(Insertion)
- 새로운 항목 를 삽입하기 위해, 키 를 검색하여 도달한 리프 노드의 부모 노드 에 삽입합니다 (검색이 실패한 경우).
- 깊이 특성(Depth Property)을 유지해야 하지만,
- 오버플로우(overflow)가 발생할 수 있습니다 (즉, 노드 가 5-노드가 될 수 있습니다).
예시: 키 30을 삽입하면 오버플로우가 발생합니다.

오버플로우와 분할(Overflow and Split)
- 5-노드 에서 오버플로우가 발생하면 분할(split) 작업을 수행합니다:
- 의 자식 노드 ㅡ>
- 의 키 ㅡ>
- 노드 (분할)
- 를 가진 3-노드, 자식 노드
- 를 가진 2-노드, 자식 노드 와
- 키 는 의 부모 노드 에 삽입되며, 새로운 root가 생성될 수 있습니다.
- 오버플로우는 부모 노드 로 전파( propagate )될 수 있습니다.

예시

(a) 하나의 항목을 가진 초기 트리;
(b) 6의 삽입;
(c) 12의 삽입;
(d) 15의 삽입, 이는 오버플로를 발생시킴;
(e) 분할, 이는 새로운 루트 노드의 생성을 야기함;
(f) 분할 후;
(g) 3의 삽입;
(h) 5의 삽입, 이는 오버플로를 발생시킴;
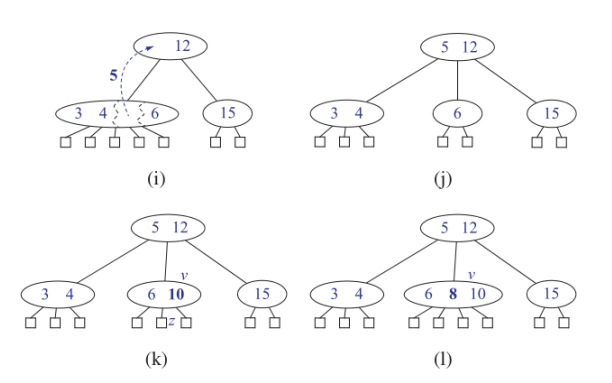
(i) 분할;
(j) 분할 후;
(k) 10의 삽입;
(l) 8의 삽입.
삽입 분석

• T가 n개의 항목을 가진 (2,4) 트리라고 가정합니다.
- • 트리 T의 높이는 O(log n)입니다.
- • 단계 1은 O(log n) 시간이 걸립니다. 왜냐하면 O(log n)개의 노드를 방문하기 때문입니다.
- • 단계 2는 O(1) 시간이 걸립니다.
- • 단계 3은 O(log n) 시간이 걸립니다. 왜냐하면 각 분할이 O(1) 시간이 걸리고 O(log n)번의 분할이 수행되기 때문입니다.
• 따라서 (2,4) 트리에 삽입하는 데는 O(log n) 시간이 소요됩니다.
Binary Search Trees
Recall: 순서 맵 (Ordered Maps)
- 키는 전체 순서에서 나옴
- 새로운 연산:
- 각각의 연산은 항목에 대한 이터레이터(iterator)를 반환:
- firstEntry(): 맵에서 가장 작은 키
- lastEntry(): 맵에서 가장 큰 키
- floorEntry(k): 인 가장 큰 키
- ceilingEntry(k): 인 가장 작은 키
- 맵이 비어 있으면 모두 end를 반환
- 각각의 연산은 항목에 대한 이터레이터(iterator)를 반환:
이진 탐색(Binary Search)
- 이진 탐색은 키로 정렬된 배열 기반 시퀀스로 구현된 순서 맵에서 get, floorEntry 및 ceilingEntry 연산을 수행할 수 있습니다.
- 높고 낮은 숫자 맞히기 게임과 유사합니다. (high-low game)
- 각 단계마다 후보 항목의 수가 절반으로 줄어듭니다.
- 단계 후에 종료됩니다.
ex) find(7)
탐색 테이블(Search Tables)
- Search Tables은 sorted sequence를 통해 구현된 ordered map입니다.
- 항목들을, 키에 따라 정렬된 array-based sequence에 저장합니다.
- 키를 비교하기 위해 외부 비교자(comparator)를 사용합니다.
- 성능:
- get, floorEntry 및 ceilingEntry 연산은 이진 탐색을 사용하여 O(log n) 시간이 걸립니다.
- insert(삽입) 연산은 최악의 경우 새로운 항목을 위한 공간을 만들기 위해 n개의 항목을 이동해야 하므로 O(n) 시간이 걸립니다.
- erase(삭제) 연산은 최악의 경우 항목을 제거한 후 n개의 항목을 압축해야 하므로 O(n) 시간이 걸립니다.
ㅡ> Binary Search Tree를 쓰자
이진 탐색 트리(Binary Search Trees)
- 이진 탐색 트리는 internal node에 키(또는 키-값 항목)를 저장하는 이진 트리로, 다음 조건을 만족합니다:
- , , 세 노드가 있을 때, 는 의 왼쪽 서브트리에 있고 는 의 오른쪽 서브트리에 있다고 가정합니다.
- 이 경우 입니다.
- External node는 항목을 저장하지 않습니다.
- 이진 탐색 트리의 중위 순회(inorder traversal)는 키를 오름차순으로 방문합니다.
검색(Search)
- 키 를 검색하기 위해, 루트에서 시작하여 아래로 내려가는 경로를 추적합니다.
- 다음에 방문할 노드는 와 현재 노드의 키를 비교한 결과에 따라 결정됩니다.
- 만약 리프(leaf) 노드에 도달하면, 해당 키는 존재하지 않는 것입니다.
- 예시: get(4):
- TreeSearch(4, root) 호출
- floorEntry와 ceilingEntry를 위한 알고리즘도 유사합니다.
삽입(Insertion)
- put(k, o) 연산을 수행하기 위해, 키 를 검색합니다 (TreeSearch 사용).
- 가 트리에 없다고 가정하고, 검색에 의해 도달한 리프 노드를 라고 합시다.
- 우리는 를 노드 에 삽입하고, 를 내부 노드로 확장합니다.
- 예시: 5를 삽입
삭제(Deletion)
- erase(k) 연산을 수행하기 위해, 키 를 검색합니다.
- 키 가 트리에 있다고 가정하고, 를 저장하고 있는 노드를 라고 합시다.
- 만약 노드 가 리프 자식 를 가지고 있다면, 우리는 트리에서 와 를 제거하는 removeExternal(w) 연산을 수행합니다. 이 연산은 와 그 부모를 제거합니다.
- 예시: 4 제거
- 제거할 키 는 두 자식이 모두 내부 노드인 노드 에 저장되어 있습니다.
- 중위 순회(inorder traversal)에서 다음에 오는 내부 노드 를 찾습니다.
- 노드 에 노드 의 키를 복사합니다.
- 노드 와 그 왼쪽 자식 (리프 노드임)를 removeExternal(z) 연산을 통해 제거합니다.
- 예시: 키 3 제거
(2, 4) Trees
다중 검색 트리(Multi-Way Search Tree)
- 다중 검색 트리는 순서가 있는 트리로, 다음과 같은 특성을 가집니다:
- 각 내부 노드는 최소 두 개의 자식을 가지며, 개의 자식을 가진 경우 개의 키-요소 쌍 을 저장합니다.
- 자식 노드 와 키 를 저장하는 노드의 경우:
- 자식 노드 의 서브트리의 키들은 보다 작습니다.
- 자식 노드 의 서브트리의 키들은 와 사이에 있습니다 ( ).
- 자식 노드 의 서브트리의 키들은 보다 큽니다.
- 리프 노드들은 항목을 저장하지 않고 자리 표시자( placeholders )로 사용됩니다
(2, 4) 트리의 노드들
2-노드 (2-node) ➔ 이진 탐색 트리
- 두 개의 자식을 가집니다.
- 하나의 키 을 포함합니다.
- 관례적으로 이고 입니다.
3-노드 (3-node)
- 세 개의 자식을 가집니다.
- 두 개의 키 를 포함합니다.
4-노드 (4-node)
- 네 개의 자식을 가집니다.
- 세 개의 키 를 포함합니다.
다중 방향 중위 순회(Multi-Way Inorder Traversal)
- binary tree에서의 inorder traversal 개념을, 다중 검색 트리(multi-way search tree)로 확장할 수 있습니다.
- 즉, 노드 의 항목 를 방문하는 것은 자식 와 의 서브트리를 재귀적으로 순회하는 중간에 이루어집니다.
- multi-way search tree는 키를 오름차순으로 방문합니다.
다중 방향 검색(Multi-Way Searching)
- binary search tree에서의 검색과 유사합니다.
- 각 내부 노드는 자식 와 키 을 가집니다.
- ( 인 경우): 검색이 성공적으로 종료됩니다.
- : 자식 에서 검색을 계속합니다.
- ( 인 경우): 자식 에서 검색을 계속합니다.
- : 자식 에서 검색을 계속합니다.
- 외부 노드에 도달하면 검색이 실패로 종료됩니다.
예시: 30을 검색
예시 : Search path for key 12 (unsuccessful search)
예시 : Search path for key 24 (successful search)
(2,4) 트리
- (2,4) 트리(2-4 트리 또는 2-3-4 트리라고도 함)는 다음과 같은 특성을 가진 다중 방향 검색 트리입니다:
- 노드 크기 특성(Node-Size Property): 모든 내부 노드는 최대 네 개의 자식을 가집니다.
- 깊이 특성(Depth Property): 모든 외부 노드는 동일한 깊이를 가집니다.
- 자식의 수에 따라 (2,4) 트리의 내부 노드는 2-노드, 3-노드 또는 4-노드라고 불립니다.
(2,4) 트리의 높이
정리(Theorem): 개의 항목을 저장하는 (2,4) 트리는 높이가 입니다.
증명(Proof):
- 를 개의 항목을 가진 (2,4) 트리의 높이라고 합시다.
- 깊이 에서 적어도 개의 항목이 있고, 깊이 에서는 항목이 없기 때문에(외부 노드만 존재), 다음과 같이 됩니다:
- 따라서, 가 됩니다.
- 따라서, 개의 항목을 가진 (2,4) 트리에서의 검색은 시간이 소요됩니다.
삽입(Insertion)
- 새로운 항목 를 삽입하기 위해, 키 를 검색하여 도달한 리프 노드의 부모 노드 에 삽입합니다 (검색이 실패한 경우).
- 깊이 특성(Depth Property)을 유지해야 하지만,
- 오버플로우(overflow)가 발생할 수 있습니다 (즉, 노드 가 5-노드가 될 수 있습니다).
예시: 키 30을 삽입하면 오버플로우가 발생합니다.
오버플로우와 분할(Overflow and Split)
- 5-노드 에서 오버플로우가 발생하면 분할(split) 작업을 수행합니다:
- 의 자식 노드 ㅡ>
- 의 키 ㅡ>
- 노드 (분할)
- 를 가진 3-노드, 자식 노드
- 를 가진 2-노드, 자식 노드 와
- 키 는 의 부모 노드 에 삽입되며, 새로운 root가 생성될 수 있습니다.
- 오버플로우는 부모 노드 로 전파( propagate )될 수 있습니다.
예시
(a) 하나의 항목을 가진 초기 트리;
(b) 6의 삽입;
(c) 12의 삽입;
(d) 15의 삽입, 이는 오버플로를 발생시킴;
(e) 분할, 이는 새로운 루트 노드의 생성을 야기함;
(f) 분할 후;
(g) 3의 삽입;
(h) 5의 삽입, 이는 오버플로를 발생시킴;
(i) 분할;
(j) 분할 후;
(k) 10의 삽입;
(l) 8의 삽입.
삽입 분석
• T가 n개의 항목을 가진 (2,4) 트리라고 가정합니다.
- • 트리 T의 높이는 O(log n)입니다.
- • 단계 1은 O(log n) 시간이 걸립니다. 왜냐하면 O(log n)개의 노드를 방문하기 때문입니다.
- • 단계 2는 O(1) 시간이 걸립니다.
- • 단계 3은 O(log n) 시간이 걸립니다. 왜냐하면 각 분할이 O(1) 시간이 걸리고 O(log n)번의 분할이 수행되기 때문입니다.
• 따라서 (2,4) 트리에 삽입하는 데는 O(log n) 시간이 소요됩니다.