
(3.1) Introduction

■ Programing Language 공부
ㅡ> Syntax 공부
ㅡ> Semantics 공부
■ Syntax
ㅡ> expressions, statements, program unit 등의 형태(form)
■ Semantics
ㅡ> expressions, statements, program unit 등의 의미(meaning)
문장과 어휘
■ 자연어
ㅡ> 'Sentence.' 들의 집합
ㅡ> 문장은 어휘(lexeme)들로 구성됨
■ PL
ㅡ> 'Statement;' 들의 집합
ㅡ> 문장은 어휘(lexeme)들로 구성됨
(3.2) lexeme + token
(3.2) The General Problem of Describing Syntax

사전
■ 자연어
단어 + <품사>
■ PL
lexeme + <token>
e.g.)


PL에서 문자열
1. Keyword (= Reserved Word)
ㅡ> 그 언어에서 특정한 의미를 가지고있는 단어들
e.g.) if, for, while
2. Identifier (ID)
ㅡ> 사용자(프로그래머)가 붙인 이름
ㅡ> 변수 이름
(3.3) Formal Methods of Describing Syntax (BNF)
(3.3) Formal Methods of Describing Syntax
ㅡ> PL의 문법을 formal하게 표현하기
■ Grammar
ㅡ> Rule들의 집합
Context Free Grammar

■ Context Free Grammar
ㅡ> 문맥에 따라 의미가 바뀌지 않는다
ㅡ> PL은 반드시 CFG여야 한다
ㅡ> Translation이 쉽기 때문
■ Context Sensitive Grammar
ㅡ> 문맥에 따라 단어의 뜻이 바뀐다.
ㅡ> 자연어
ㅡ> Translation이 어려움
e.g.)
"배를 타고 배를 먹으니 배가 아프다"
ㅡ> '배'라는 단어가 문맥에 따라 의미가 다르다
(3.3.1) Backus-Naur Form (BNF)
ㅡ> 문법을 formal하게 나타내려고 만든 것
■ Metalanguage
ㅡ> 다른 언어를 설명하거나 정의하는데 사용되는 언어
■ Meta라는 단어
e.g.) Meta data
ㅡ> 데이터를 위한 데이터
ㅡ> 책의 인덱스
ㅡ> 파일의 index 파일
e.g.) 메타인지
ㅡ> 인지에 대한 인지
■ BNF notation

1. Rule
2. Non-Terminal
3. Or
e.g.)

■ Rule


■ Terminal
ㅡ> 그 언어의 단어
ㅡ> 실제 쓰는 문장은 Terminal의 나열이다.
ㅡ> Non-Terminal은 문법을 표현할 때만 쓴다.
■ Non-terminal
ㅡ> 문법을 표현하기 위한 문자열
ㅡ> 반드시 rule의 왼쪽에 한번 나와야 한다
■ Grammar

ㅡ> Rule들의 집합
■ Start Symbol
ㅡ> 왼쪽 맨 위의 non-terminal
ㅡ> 여기서부터 rule을 적용해서 유도하는 과정이 Derivation이다.
■ OR

ㅡ> Rule을 하나로 합칠 때 씀
■ 재귀 (Recursive)


ㅡ> 갯수가 정해지지 않은것을 정의하는 방법
(3.3.1.5) Grammars and Derivations
EX 3.1

■ Derivation
ㅡ> 문법에 맞나 검사하는 것
ㅡ> Start Symbol에서부터 rule을 적용하여 문장들을 유도
ㅡ> 마지막엔 다 Terminal이 되야 함
ㅡ> 유도가 안되면 syntax error

■ leftmost derivation
ㅡ> non-terminal 이 여러개 있을 때, 왼쪽부터 처리
ㅡ> Parse Tree에서도 마찬가지, Pre-Order
3.3.1.6 Parse Trees
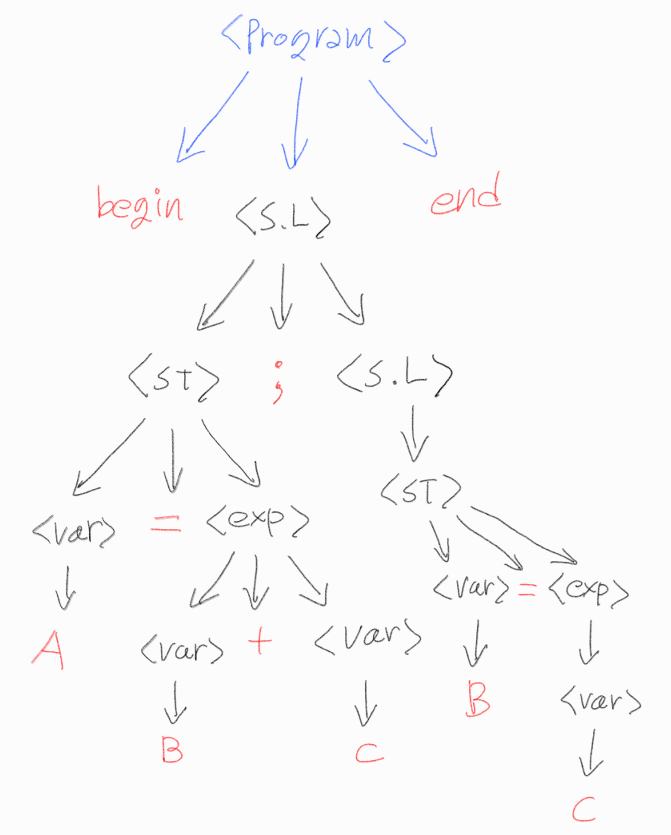
- Parsing = Syntax Analysis
- Parsing은 컴파일러 뿐만 아니라, 모든 입력을 받아들이는 프로그램은 다 필요하다. 그래야 해석된다.
- Derivation을 tree형태로 나타낸다. (Pre-Order)
- Start Symbol이 root가 된다.
- 모든 노드가 terminal이 되면 끝난다.
(3.3.1.7) (P) 모호성 (Ambiguity)
ㅡ> 여러 해석이 가능한 문장
ㅡ> 2개 이상의 parse tree가 나온다.
e.g.)
우리는 예쁜 그녀의 강아지를 봤다.
(1) 예쁜 그녀
(2) 예쁜 강아지
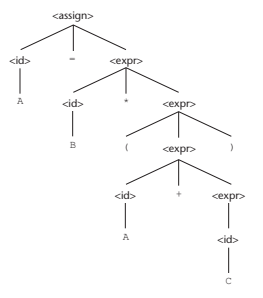
e.g.) 배정문 A = B + C * A

(S) 우선순위를 정한다

1. 다른 우선순위 ㅡ> 연산자 우선순위
2. 같은 우선순위 ㅡ> 연산자 결합법칙
ㅡ> 모호성을 해결해 준다.
(3.3.1.8) 연산자 우선순위 (Operator Precedence)
연산자가 여러개 나왔을 때
먼저 연산해야 하는 것
e.g.) 배정문 수정

ㅡ> 이러면 parse tree 1개만 나온다
ㅡ> 우선순위가 높은 연산자일 수록 문법의 아래에 위치한다.
ㅡ> 같은 우선순위(덧셈, 뺄셈)면 같은 레벨에 정의할 수 있다.
(3.3.1.9) 연산자 결합법칙 (Associativity of Operators)
하나의 식에 같은 우선순위의 연산자들이 나타났을 때
좌결합 (left associate) ㅡ> 왼쪽부터 처리
우결합 (right associate) ㅡ> 오른쪽부터 처리
ㅡ> 우리가 사용하는 대부분의 연산자는 좌결합
ㅡ> 예외적으로 제곱같은건 우결합
e.g.)
2**3**4
ㅡ> 2**(3**4) // 우결합

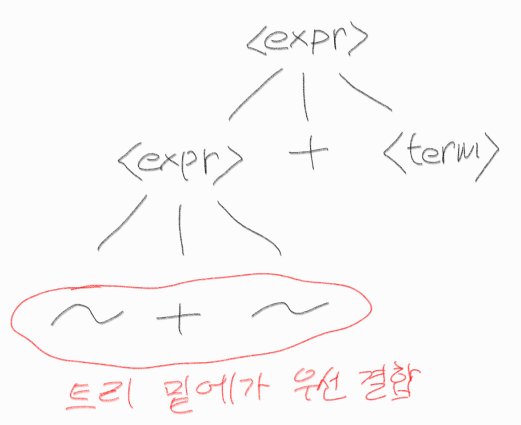
좌결합이면 식의 왼쪽에서 재귀한다. (rule 에서)
트리의 밑에 있을 수록 우선순위가 높다. (밑에 있는 것부터 결합)
(3.3.1.10) if-else 모호성


if문이 재귀할 때
else는 어떤 if에 붙은 else인가?
ㅡ> (P) 모호함
(S)
(1) 보통, else에 가까운 if에 붙인다.
(2) 먼 if에 붙이려면, 가까운 if문을 블록으로 만든다.
(3.3.2) 확장된 BNF
ㅡ> 쓰고읽기 좋게, BNF를 확장
■ square bracket '[ ]'


ㅡ> option
ㅡ> 0 or Once (안나오거나, 한번나온다)
■ Braces '{ }'

ㅡ> 재귀
ㅡ> 0 or More
■ (ㅣ)


ㅡ> or
ㅡ> 저중에 하나

(3.3.3) Grammars and Recognizers

yacc : rule을 집어넣으면, syntax analysis하는 프로그램을 자동생성 해준다.
yacc = yet another compiler compiler
ㅡ> 컴파일러를 만드는 컴파일러
(3.4) 이후 생략 ㅡ> '컴파일러' 과목을 들어라!
'CS > 프로그래밍 언어론' 카테고리의 다른 글
| [양PL] 6장 Data Type (0) | 2024.04.30 |
|---|---|
| [양PL] 5장 Names, Bindings, and Scopes (0) | 2024.04.25 |
| [양PL] 4장 Laxical and Syntax Analysis (0) | 2024.04.04 |
| [양PL] 2장 언어의 진화 (0) | 2024.03.18 |
| [양PL-1] 1장 서론 (0) | 2024.03.12 |