
File and File system

■ 메모리
ㅡ> 주소를 통해 접근
■ 파일
ㅡ> 이름을 통해 접근
ㅡ> data를 저장하는 목적으로만 쓰는게 아니라, 장치들도 file로 관리한다 (ex. 하드디스크1, 하드디스크2) (device special file)
■ Operation
ㅡ> create/delete 파일 생성/삭제
ㅡ> read/write 읽기/쓰기
ㅡ> reposition (lseek) 파일 포인터를 원하는 위치로 이동 (ex. 특정 바이트부터 읽거나 쓰고 싶을 때)
ㅡ> open/close 파일의 metadata를 디스크에서 메모리로 올림
■ File attribute (metadata)
ㅡ> 파일을 관리하기 위한 정보들
■ File system
ㅡ> OS에서 파일을 관리하는 부분
Directory and Logical Disk

■ 디렉토리
ㅡ> 이 디렉토리에 속한 파일들의 메타데이터를 보관하고 있는 '파일'
■ Operation
■ 디스크
ㅡ> 논리적 디스크 (파티션) (ex. C드라이브, D드라이브)
ㅡ> 물리적 디스크 (하드웨어)
논리적 디스크
ㅡ> OS가 보는 디스크는 논리적 디스크이다.
ㅡ> 파티션을 file system이나 swap area용도로 쓸 수 있다
open(), read()

open()하면 파일의 메타데이터가 메모리에 올라간다


■ open("/a/b")
ㅡ> 시스템콜
ㅡ> root 디렉토리의 메타데이터를 OS가 알고있으니 메모리에 올린다
ㅡ> 그뒤에 메타데이터에 나온 파일위치를 통해 연쇄적으로 메타데이터를 open file table에 올린다 (시스템에 하나인 테이블)
ㅡ> PCB에 '프로세스가 open한 메타데이터의 포인터'가 나열된 테이블이 있다 (프로세스별로 부여된 테이블)
ㅡ> 그 배열(테이블)의 인덱스가 파일디스크립터이다
ㅡ> 그 파일디스크립터를 return한다 (fd에 반환)
■ read(fd)
ㅡ> 시스템콜
ㅡ> b의 파일디스크립터인 fd를 통해 read한다
ㅡ> 파일 내용을 사용자 프로그램에 직접 주는게 아니라,
OS 메모리 일부에 올려놓고, 그 내용을 카피해서 사용자 프로그램에 전달 한다
ㅡ> 동일한 파일의 동일한 위치의 요청이 오면, DISK로 가는게 아니라 OS에 올려둔걸 바로 전달 (버퍼 캐슁)
ㅡ> 즉, 버퍼에 있든없든 CPU가 OS에 넘어가고, 버퍼에있으면 바로 넘겨주고 없으면 디스크에서 OS로 올려둔뒤 카피해준다
ㅡ> 이 경우에 항상 CPU가 OS에 넘어가는 버퍼캐슁이기 때문에 LRU나 LFU알고리즘을 사용 할 수 있다 (버추얼메모리에선 clock 알고리즘 써야했다)
■ 글로벌 테이블
ㅡ> 시스템에 하나만 존재
ㅡ> metadata 올려두는 테이블
■ 프로세스별 테이블
ㅡ> 프로세스가 open한 메타데이터의 포인터를 나열
ㅡ> 프로세스가 파일의 어느 위치를 접근하고 있는지 (offset)
File Protection

■ 접근권한
ㅡ> 메모리는 그 프로세스만 써서 접근권한(read/write/execution)만 있으면 됐다
ㅡ> 파일은 여러 프로세스가 써서, '어떤 프로세스에게 권한이 있는지', '어떤 연산이 가능한지' 이 2가지가 있어야 한다
파일 프로텍션에서 접근권한을 제어하는 방법을 크게 3가지정도로 생각할 수 있다
■ Access control Matrix
ㅡ> 행렬로 제어
ㅡ> 빈칸이 많아 낭비공간이 많아서 linked-list로 만들 수도 있음 ▶ Access control list, Capability
■ Grouping
ㅡ> 세 그룹으로 구분
ㅡ> 파일의 소유주(owner), 같은 그룹의 사용자(group), 외부 사용자(public)
ㅡ> 각 그룹에 read, write, execution 3개의 비트가 존재
ㅡ> 9비트만 필요, 일반적으로 이 방식을 채택
■ Password
ㅡ> 파일별 패스워드, 디렉토리별 패스워드, 접근 권한별 패스워드 등 여러가지 방법
File system의 Mounting
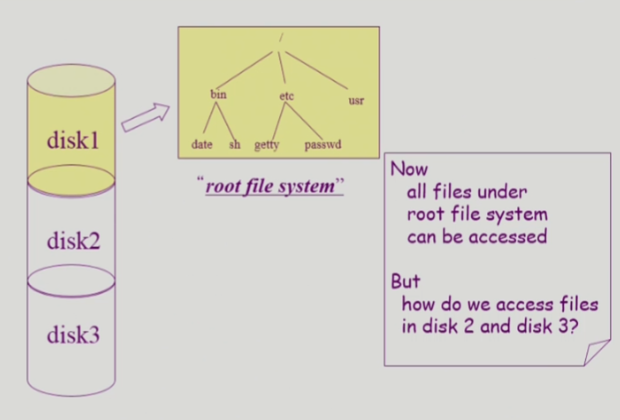

■ 디스크(파티션)마다 각각 파일 시스템이 있다
ㅡ> 파일 시스템마다 1개의 루트가 있다
■ 마운트
ㅡ> (what) 파일 시스템의 루트를 특정 디렉토리에 연결
ㅡ> (why) 여러 파티션의 파일 시스템을 하나로 통합하기 위함
ex) 위 그림
usr디렉토리에 disk3의 파일 시스템을 마운트하였다
Access Methods

■ 순차접근
ㅡ> 처음부터 차례대로 접근해야 함.
ㅡ> 반드시 a->b->c 순서대로 접근해야 되고, 중간과정을 못 건너뜀
ㅡ> ex) 카세트 테이프
■ 직접 접근
ㅡ> 원하는 위치에 바로 접근
ㅡ> 중간과정 건너뛰어서 a->c로 접근할 수 있음
ㅡ> ex) LP레코드 판
DISK에서 File Data의 Allocation

Contiguous Allocation
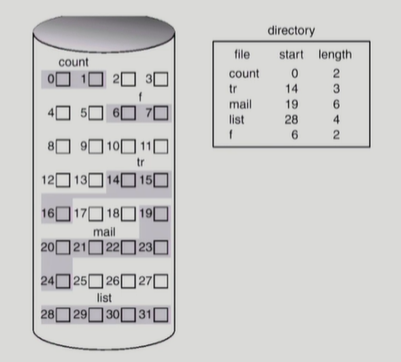
■ 연속 할당
ㅡ> 하나의 파일이 DISK에서 연속된 블록을 차지
ㅡ> 시작 위치(start)와 길이(length)로 파일을 찾음
ex) 위 그림
디렉토리에 file이름과 start, length 정보가 있다
ㅡ> count파일 시작위치0, 길이2
ㅡ> mail파일 시작위치19, 길이6
ㅡ> 등등

■ 단점
ㅡ> 외부조각 가능성 ◀ 파일을 무조건 연속적으로 할당해야되기 때문에, 파일을 쪼개서 빈공간을 채우는게 불가능
ㅡ> 파일의 크기를 키우는데 제약이 있다 ▶파일 grow를 예상해서 미리 빈공간을 할당해놓으면, 그것은 내부조각이다 (낭비)
■ 외부조각vs내부조각
ㅡ> 외부조각 : 할당 가능한데 할당되지 않은 조각
ㅡ> 내부조각 : 할당은 되었는데 사용되지 않은 조각
■ 장점
ㅡ> 빠른 I/O가능 ▶ DISK는 대부분의 접근시간이 헤더가 움직이는 시간인데, 연속할당 방식은 헤더 동선의 낭비가 적음
ㅡ> 공간효율보다 속도가 중요한 Realtime이나 Swapping용으로 쓰기 좋음
ㅡ> 직접 접근이 가능
Linked Allocation

■ 연결 할당
ㅡ> 시작위치(start)에 가면 그 블록이 다음 블록의 위치를 알려줌

■ 장점
ㅡ> 외부조각 발생x
■ 단점
ㅡ> 순차접근을 해야 함
ㅡ> Reliable문제 : 한 섹터가 고장나면 뒷내용은 다 못찾음
ㅡ> 각 블록에 포인터가 필요해서 공간낭비 (섹터 : 512바이트, 포이터 : 4바이트)
(S) File allocation table (FAT)
ㅡ> 포인터 별도의 위치에 보관하여 realiable과 공간효율 문제 해결
Indexed Allocation
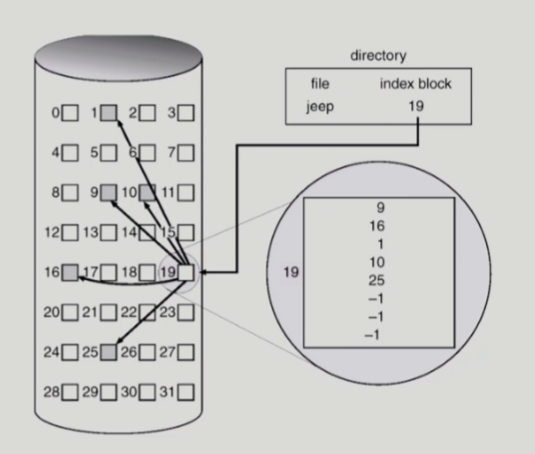
■ 인덱스 할당
ㅡ> 디렉토리에 인덱스블록의 위치를 저장
ㅡ> 인덱스 블록에 파일의 블록위치가 순서대로 있음

■ 장점
ㅡ> 외부조각 발생x
ㅡ> 직접 접근 가능
■ 단점
ㅡ> 아무리 작은 파일이어도 블록이 2개 필요함 (공간낭비)
ㅡ> 너무 큰 파일은 하나의 인덱스 블록으로 다 표현 못함 ▶ (S) linked scheme, multi-level index
■ linked scheme
ㅡ> 인덱스 블록의 마지막 포인터는 또다른 인덱스 블록
■ multi-level index
ㅡ> 2단계 페이징 테이블 쓰듯이, 인덱스를 계층화 시킴
ㅡ> 첫 인덱스 블록에서 바로 파일 위치를 가리키는게 아니라, 또다른 인덱스 블록을 가리키고 거기서 파일 위치를 가리키는 식
UNIX 파일 시스템

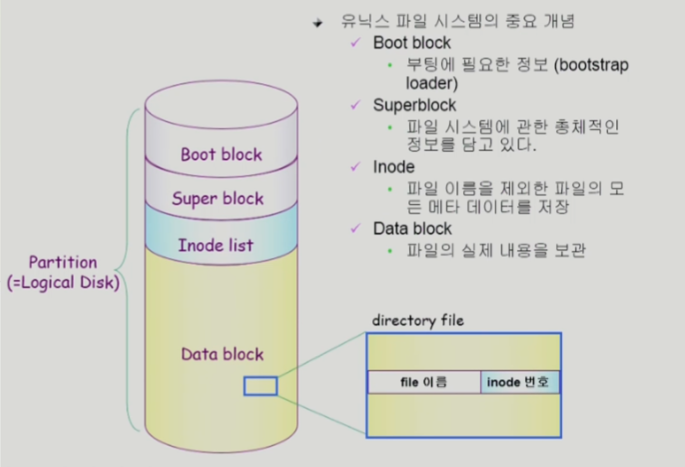
■ Boot block
ㅡ> 어떤 파일 시스템이던 Boot block이 맨 앞에 옴 (0번 블록)
ㅡ> 컴퓨터 전원키면 0번 블록인 Boot block을 메모리에 올려서 부팅함
ㅡ> 부팅정보가 들어있음 (OS 커널 위치가 어디인지 등)
■ Super block
ㅡ> 파일 시스템의 총체적인 정보 (구조와 상태)
ㅡ> 블록크기, 전체 블록 수, 빈 블록 수, inode 목록 등
■ Inode list
ㅡ> 디렉토리는 파일 이름만 가지고 있다
ㅡ> 대부분의 메타데이타들은 Inode에 보관
ㅡ> 파일 하나당 하나의 Inode가 부여된다
ㅡ> 위치정보는 Indexed Allocation을 변형해서 사용
■ 위치정보
ㅡ> direct blocks : 바로 파일위치를 가리키는 포인터들
ㅡ> single indirect : 인덱스 블럭의 위치를 가리키는 포인터들
ㅡ> double indirect : 인덱스 블럭이 2단계로 계층화
ㅡ> triple indirect : 인덱스 블럭이 3단계로 계층화
ㅡ> 파일 크기가 클 수록 밑에있는거 사용
FAT File system

■ FAT
ㅡ> 파일의 metadata중 일부를 보관 (파일의 클러스터 할당 정보)
ㅡ> 나머지는 디렉토리에 보관
ㅡ> (why) linked-allocation방식의 단점을 해결 ▶ 직접접근 가능, Data 유실되도 FAT으로 찾으면 되고, FAT자체도 2카피 이상 있어서 Reliable문제 해결
■ data block과 1:1할당되는 FAT 배열 ▶ FAT 배열에는 각 data block의 다음 블럭의 번호를 적어둠
■ 디렉토리는 파일의 시작위치만 가지고 있고, 그 다음 연결은 FAT에서 찾음
■ EOF = 파일의 끝부분으로 약속된 숫자
■ 장점
ㅡ> 직접 접근이 가능 ▶ DISC를 꺼내보며 다음블록을 찾는게 아니라, 메모리에 올라와있는 FAT 테이블에서 위치를 찾아내고 DISC에서 바로 직접 접근 ▶ 다만, FAT에서 위치를 찾아내는 과정은 순차 접근임
Free-Space Management
외부조각, 비어있는 블록은 어떻게 관리할까?
Bit map
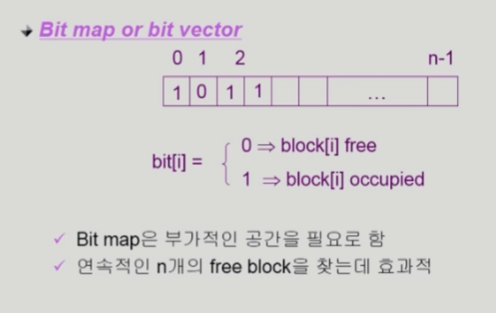
■ Bit map
ㅡ> 0 : 해당 블록이 비어 있음
ㅡ> 1 : 해당 블록이 사용 중
■ 특징
ㅡ> Bit map을 저장하기 위한 메모리가 필요
ㅡ> 연속된 n개의 빈 블록을 빠르게 찾을 수 있다 ▶ 디스크 헤더 동선 최소화
Linked-List


■ 비어있는 각 블록이 다음 비어있는 블록의 위치를 가리키는 포인터를 가짐
시스템이 비어있는 블록의 첫번째 위치만 가지고 있다가
그 다음 위치는 블록안의 포인터로 알아냄
■
장점 : bit-map에 비해 추가적인 공간낭비가 없음
단점 : 연속적인 빈 공간 찾기 힘듬
Grouping

■ index형식으로 grouping
■ 첫번째 빈 블록에 n개의 포인터
ㅡ> n-1개 포인터는 빈 블록 가리킴
ㅡ> 마지막 1개의 포인터는 또 n개의 포인터가 있는 블록 가리킴
■ 단점 : 연속적인 빈 공간 찾기 힘듬
Counting

■ 한쌍의 정보
ㅡ> (빈 블록의 첫번째 위치, 거기서부터 몇개가 빈 블록인가)
Directory Implementation

■ 디렉토리
ㅡ> 디렉토리 밑의 파일의 metadata를 보관
ㅡ> 어떤식으로 구현할 것인가
■ Linear list 방식
ㅡ> <파일 이름, 파일 metadata>
ㅡ> 각 metadata 크기가 고정(파일이름은 몇바이트를 쓰고.. 접근권한은 몇바이트..파일사이즈는 몇바이트.. 등 고정) ▶ 특정 metadata 필드 시작위치를 알아내기 쉬움
ㅡ> 구현이 간단
ㅡ> 특정 파일 있는지 검색하는데 오래걸림 (비효율적)
■ Hash Table 방식
ㅡ> 파일의 이름에 해쉬 함수를 적용 ▶ 특정 범위안의 숫자로 변환하여 인덱스로 삼음
ㅡ> 검색시간 단축 ◀ 찾고싶은 파일에 해쉬함수 적용해서 인덱스 찾아냄
ㅡ> 단점 : Collision (서로 다른 파일의 해시함수 결과 겹침) ▶ 해결법은 자료구조 시간에...

■ metadata
ㅡ> 디렉토리에 직접보관하기도 하고
ㅡ> 디렉토리에 포인터 두고 다른 곳에 보관하기도 함 (ex. inode, FAT)
■ 긴 파일 이름
ㅡ> 엔트리에 name 크기는 고정임
ㅡ> 엔트리 크기보다 커지면, 엔트리 마지막에 포인터를 두고, 이름의 나머지 부분을 다른 공간에 둠
VFS and NFS

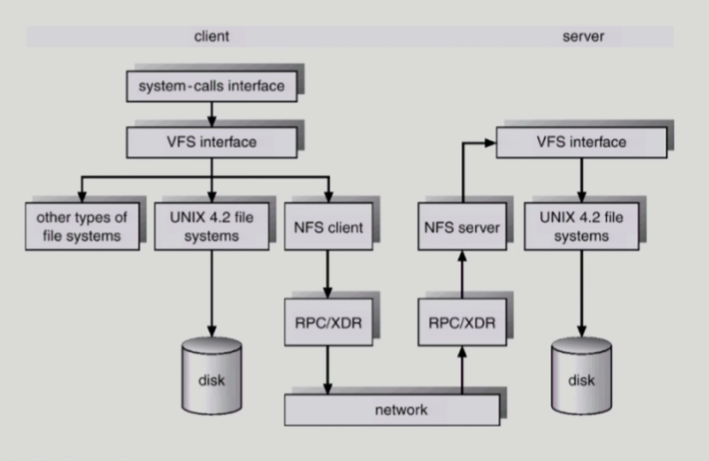
■
파일 시스템마다 다른 시스템콜 인터페이스면 사용자가 힘들다
그래서 VFS를 사용
ㅡ> 어떤 파일 시스템이든 사용자는 VFS 인터페이스로 접근
■ NFS
ㅡ> client가 server의 파일 시스템에 접근할 때는 NFS를 사용
Page Cache and Buffer Cache (이해안됨)

■ Page Cache
ㅡ> 페이지 프레임 (swap area보다 빨라서 캐쉬로 봄)
ㅡ> clock 알고리즘 사용
■ Buffer Cache
ㅡ> 파일을 disc에서 꺼내올 때, read() 요청한 사용자한테만 주는게 아니라, OS 메모리에 올려놓고 카피해줌. ▶ 다른 사용자가 요청하면 disc까지 안가고 메모리에서 바로 카피할 수 있음
ㅡ> LRU, LFU 사용
■ Unified Buffer Cache
ㅡ> Page Cache와 Buffer Cache를 합쳐서 같이 관리
ㅡ> 버퍼캐쉬의 단위(block)와 페이지 캐쉬의 단위(frame)를 통일해서 같은 크기로 만듬 ▶ 빈공간을 필요에따라 버퍼캐쉬로 쓰거나 페이지 캐쉬로 쓰거나 선택
■ Memory-Mapped I/O
ㅡ> open(), read() 시스템콜이랑 다른 방식
ㅡ> 프로세스의 주소공간 일부를 File에 매핑 ▶메모리 접근 연산으로 파일 I/O 수행


■ Unified Buffer Cache 사용x
ㅡ> read()/write() : 버퍼캐쉬에 있는지 확인하고, 없으면 파일 시스템에서 꺼내옴. 버퍼캐쉬에서 프로세스로 카피해줌
ㅡ> memory-mapped I/O : mmap()시스템콜 사용, 버퍼캐쉬(OS)에 있는걸 페이지 캐쉬(프로세스)로 카피해주면, 그게 파일과 mapped된 것 (?)
read/wirte시스템콜은 항상 OS에게 요청
memory-mapped는 한번 올라오면 OS필요x
■ Unified Buffer Cache 사용o
ㅡ> memory-mapped I/O : 버퍼캐쉬를 페이지캐쉬처럼 씀

code영역은 코드를 버추얼메모리에 직접올리지 않고
실행파일과 매핑한다
그래서 물리적메모리에서 방출할때도 sawp area로 가지 않는다
ㅡ> file system으로 방출하며 write 내용을 반영

mmap()을 하면
커널이 파일을 버추얼메모리와 매핑해준다
그리고 페이지폴트가 날때 물리적 메모리의 페이지 캐쉬에 파일내용이 올라간다
프로세스가 이 물리적 메모리에 올라온 내용을 커널없이 마음대로 수정한다
그리고 물리적 메모리에서 내려갈때 swap area가 아니라 file system으로 내려가며 write된 내용을 반영한다
다른 프로세스가 같은 파일을 요청하면
물리적 메모리의 페이지 캐쉬를 그 프로세스에게도 매핑해준다
페이지 캐쉬를 두 프로세스가 공유하게 된다
ㅡ> OS가 중재하지 않기 때문에 동기화문제 발생 가능
'CS > 운영체제' 카테고리의 다른 글
| [OS] Disk Management & Scheduling (0) | 2025.02.25 |
|---|---|
| [OS] Virtual Memory (0) | 2025.02.11 |
| 인터페이스 (1) | 2025.02.04 |
| [OS] Memory Management (0) | 2025.01.22 |
| [OS] DeadLock (교착상태) (0) | 2025.01.17 |