
■ SELECT
ㅡ> 열을 선택
■ FROM
ㅡ> 테이블 선택
ㅡ> 괄호안에 인라인 뷰를 써서 테이블을 만들어낼 수도 있음
ㅡ> 뷰 : DB에 있는 테이블x 동적으로 만든 인스턴스 테이블o
■ WHERE
ㅡ> SELECT조건 (행을 선택)
ㅡ> GROUP BY보다 먼저 실행, 집계함수 불가
■ GROUP BY 열
ㅡ> 해당 열에서 같은 값을 가진 행끼리 하나의 그룹으로 뭉쳐줍니다
ㅡ> NULL 행도 포함
■ HAVING
ㅡ> GROUP BY의 조건 (행을 결정)
ㅡ> 집계함수 가능
■ ORDERED BY 열
ㅡ> ASC : 오름차순, 디폴트
ㅡ> DESC : 내림차순
FROM에서 2개 이상의 테이블을 가져왔을 때
'테이블.칼럼' 형식을 쓴다
'칼럼'으로 써도 되는데, 중복인경우 오류가 뜬다
NULL
■ MIN/MAX
ㅡ> NULL이 아닌 행들만 비교
■ SUM
ㅡ> NULL을 무시
■ 사칙연산
ㅡ> NULL과의 사칙연산 결과는 NULL
함수
■ COALESCE(a,b)
ㅡ> null이 아닌 값 반환
ㅡ> null을 만나면 다음 자리수로 미룸
COALESCE(NULL, 1, 2) = 1
COALESCE(NULL, NULL, 2) = 2
COALESCE(1, 2, NULL) = 1
■ ISNULL(a,b) / NVL(a,b)
ㅡ> ISNULL : SQL server
ㅡ> NVL : 오라클
ㅡ> a가 null이면 b를 반환
■ NULLIF(a,b)
ㅡ> a와 b가 같으면 NULL을 반환
join
카타시안 곱
ㅡ> 적절한 join조건이 없는 경우
ㅡ> 모든 가능한 조합을 만들어냄
join 할때마다 테이블을 오른쪽에 붙임
inner join ㅡ> 겹치는 행만 살린다
outer join ㅡ> 특정 테이블의 행을 전부 살려서 join한다. 반대쪽 테이블에 해당 행이 없을시에 null값을 붙인다
R ㅡ> 오른쪽 살림
L ㅡ> 왼쪽 살림
FULL ㅡ> 둘 다 살림
USING
ㅡ> 조인할때 공통된칼럼 지정
ㅡ> ON과는 다르게 칼럼 이름이 같아야
공부
_ BETWEEN _ AND _
집합연산자
UNION
ㅡ> 두 쿼리 결과를 합침
ㅡ> 중복행 제거
ㅡ> UNION ALL : 중복행 유지
ㅡ> JOIN이 옆으로 합치는거라면 UNION은 위아래로 합치는 것
ㅡ> ORDER BY보다 먼저 실행

GROUP BY 집계함수
GROUPING SETS()
ㅡ> 원하는 칼럼으로 그룹화하여 집계
ROLLUP (a, b)
ㅡ> 칼럼을 계층화해서 순차적 집계
ㅡ> ex) a,b 조합별 합계, a 합계, 전체 합계
CUBE ()
ㅡ> 가능한 모든 조합 집계
GORUPING(column)
ㅡ> 0or 1 반환
ㅡ> 0 : 소계
ㅡ> 1 : 집계
ㅡ> 노랭이 78번
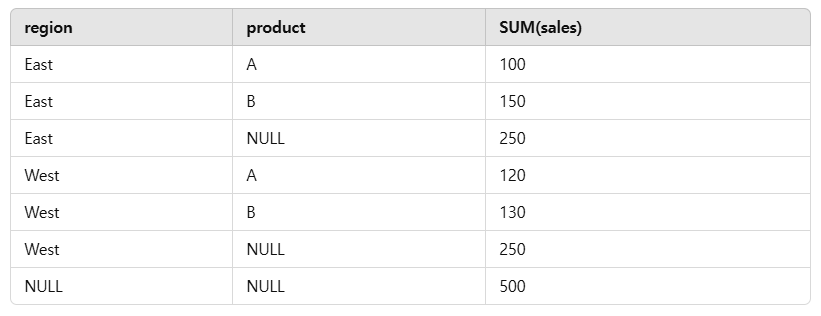
ROLLUP
ㅡ> 위에서부터 점진적으로 집계
ㅡ> 상위 집계와 하위 집계를 모두 포함하는 계층적인 집계를 수행
- region과 product별 합계
- 각 region의 전체 합계
- 전체 합계
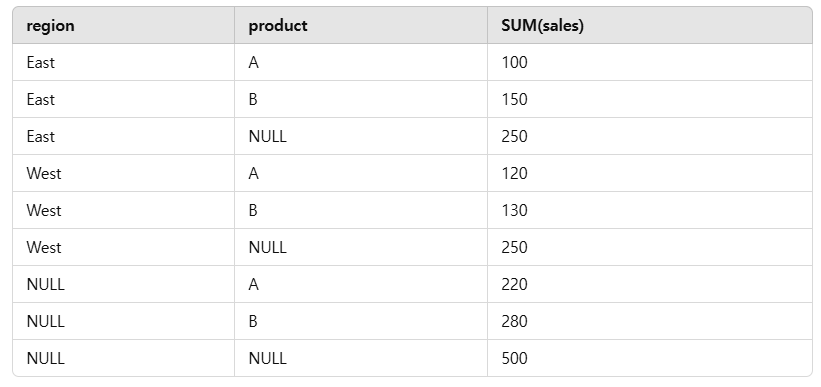
CUBE
ㅡ> 모든 가능한 조합에 대한 집계를 계산
- region과 product별 합계
- 각 region별 합계
- 각 product별 합계
- 전체 합계
계층 구조
ㅡ> 트리구조
START WITH
ㅡ> 계층 구조를 전개하는 시작점
CONNECT BY PRIOR
ㅡ> PROIOR에 붙은게 이전행의 요소
ㅡ> PRIOR에 붙은게 부모면 상향식, 자식이면 하향식으로 트리 전개
ORDER SIBLINGS BY
ㅡ> 형제 노드 사이의 정렬을 지정
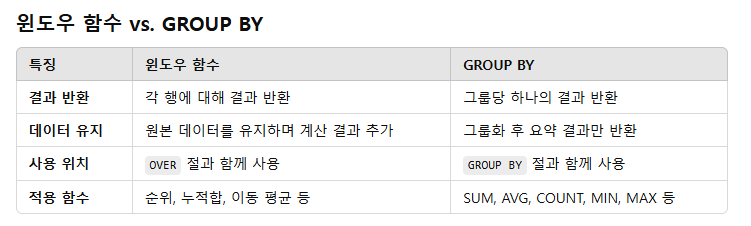
윈도우함수
ㅡ> 창문(네모난 틀)안에서 계산하는 느낌
원본 테이블 그룹화 안하고
인스턴스로 그룹화해서 계산
ex)
SELECT
부서,
사원ID,
월급,
ROW_NUMBER() OVER (PARTITION BY 부서 ORDER BY 월급 DESC) AS 순위
FROM 직원;
ROW_NUMBER()와 OVER절 안에 있는 것들
- LAG(column, offset, default):
- column: 참조할 대상 열.
- offset: 이전 몇 번째 행의 값을 참조할지 지정 (기본값은 1).
- default: 참조하려는 행이 없을 경우 반환할 기본값 (기본값은 NULL).
- LEAD(column, offset, default):
- column: 참조할 대상 열.
- offset: 다음 몇 번째 행의 값을 참조할지 지정 (기본값은 1).
- default: 참조하려는 행이 없을 경우 반환할 기본값 (기본값은 NULL).
UNBOUNDED
ㅡ> 범위의 한쪽 끝을 무제한으로 설정
CURRENT ROW
ㅡ> 현재 행
X PRECEDING
ㅡ> 현재행의 값에서 X이전까지
X FOLLOWING
ㅡ> 현재 행에서 X이후까지
'CS > 정보처리기사' 카테고리의 다른 글
| SQLD 관리 구문 (0) | 2024.11.16 |
|---|---|
| [SQLD] 1-2 데이터 모델과 SQL (1) | 2024.11.08 |
| [SQLD] 1. 데이터 모델링의 이해 (1) | 2024.11.05 |
| 4. 프로그래밍 언어 활용 (0) | 2024.07.09 |
| 2. 소프트웨어 개발 (0) | 2024.07.04 |
■ SELECT
ㅡ> 열을 선택
■ FROM
ㅡ> 테이블 선택
ㅡ> 괄호안에 인라인 뷰를 써서 테이블을 만들어낼 수도 있음
ㅡ> 뷰 : DB에 있는 테이블x 동적으로 만든 인스턴스 테이블o
■ WHERE
ㅡ> SELECT조건 (행을 선택)
ㅡ> GROUP BY보다 먼저 실행, 집계함수 불가
■ GROUP BY 열
ㅡ> 해당 열에서 같은 값을 가진 행끼리 하나의 그룹으로 뭉쳐줍니다
ㅡ> NULL 행도 포함
■ HAVING
ㅡ> GROUP BY의 조건 (행을 결정)
ㅡ> 집계함수 가능
■ ORDERED BY 열
ㅡ> ASC : 오름차순, 디폴트
ㅡ> DESC : 내림차순
FROM에서 2개 이상의 테이블을 가져왔을 때
'테이블.칼럼' 형식을 쓴다
'칼럼'으로 써도 되는데, 중복인경우 오류가 뜬다
NULL
■ MIN/MAX
ㅡ> NULL이 아닌 행들만 비교
■ SUM
ㅡ> NULL을 무시
■ 사칙연산
ㅡ> NULL과의 사칙연산 결과는 NULL
함수
■ COALESCE(a,b)
ㅡ> null이 아닌 값 반환
ㅡ> null을 만나면 다음 자리수로 미룸
COALESCE(NULL, 1, 2) = 1
COALESCE(NULL, NULL, 2) = 2
COALESCE(1, 2, NULL) = 1
■ ISNULL(a,b) / NVL(a,b)
ㅡ> ISNULL : SQL server
ㅡ> NVL : 오라클
ㅡ> a가 null이면 b를 반환
■ NULLIF(a,b)
ㅡ> a와 b가 같으면 NULL을 반환
join
카타시안 곱
ㅡ> 적절한 join조건이 없는 경우
ㅡ> 모든 가능한 조합을 만들어냄
join 할때마다 테이블을 오른쪽에 붙임
inner join ㅡ> 겹치는 행만 살린다
outer join ㅡ> 특정 테이블의 행을 전부 살려서 join한다. 반대쪽 테이블에 해당 행이 없을시에 null값을 붙인다
R ㅡ> 오른쪽 살림
L ㅡ> 왼쪽 살림
FULL ㅡ> 둘 다 살림
USING
ㅡ> 조인할때 공통된칼럼 지정
ㅡ> ON과는 다르게 칼럼 이름이 같아야
공부
_ BETWEEN _ AND _
집합연산자
UNION
ㅡ> 두 쿼리 결과를 합침
ㅡ> 중복행 제거
ㅡ> UNION ALL : 중복행 유지
ㅡ> JOIN이 옆으로 합치는거라면 UNION은 위아래로 합치는 것
ㅡ> ORDER BY보다 먼저 실행
GROUP BY 집계함수
GROUPING SETS()
ㅡ> 원하는 칼럼으로 그룹화하여 집계
ROLLUP (a, b)
ㅡ> 칼럼을 계층화해서 순차적 집계
ㅡ> ex) a,b 조합별 합계, a 합계, 전체 합계
CUBE ()
ㅡ> 가능한 모든 조합 집계
GORUPING(column)
ㅡ> 0or 1 반환
ㅡ> 0 : 소계
ㅡ> 1 : 집계
ㅡ> 노랭이 78번
ROLLUP
ㅡ> 위에서부터 점진적으로 집계
ㅡ> 상위 집계와 하위 집계를 모두 포함하는 계층적인 집계를 수행
- region과 product별 합계
- 각 region의 전체 합계
- 전체 합계
CUBE
ㅡ> 모든 가능한 조합에 대한 집계를 계산
- region과 product별 합계
- 각 region별 합계
- 각 product별 합계
- 전체 합계
계층 구조
ㅡ> 트리구조
START WITH
ㅡ> 계층 구조를 전개하는 시작점
CONNECT BY PRIOR
ㅡ> PROIOR에 붙은게 이전행의 요소
ㅡ> PRIOR에 붙은게 부모면 상향식, 자식이면 하향식으로 트리 전개
ORDER SIBLINGS BY
ㅡ> 형제 노드 사이의 정렬을 지정
윈도우함수
ㅡ> 창문(네모난 틀)안에서 계산하는 느낌
원본 테이블 그룹화 안하고
인스턴스로 그룹화해서 계산
ex)
SELECT
부서,
사원ID,
월급,
ROW_NUMBER() OVER (PARTITION BY 부서 ORDER BY 월급 DESC) AS 순위
FROM 직원;
ROW_NUMBER()와 OVER절 안에 있는 것들
- LAG(column, offset, default):
- column: 참조할 대상 열.
- offset: 이전 몇 번째 행의 값을 참조할지 지정 (기본값은 1).
- default: 참조하려는 행이 없을 경우 반환할 기본값 (기본값은 NULL).
- LEAD(column, offset, default):
- column: 참조할 대상 열.
- offset: 다음 몇 번째 행의 값을 참조할지 지정 (기본값은 1).
- default: 참조하려는 행이 없을 경우 반환할 기본값 (기본값은 NULL).
UNBOUNDED
ㅡ> 범위의 한쪽 끝을 무제한으로 설정
CURRENT ROW
ㅡ> 현재 행
X PRECEDING
ㅡ> 현재행의 값에서 X이전까지
X FOLLOWING
ㅡ> 현재 행에서 X이후까지
'CS > 정보처리기사' 카테고리의 다른 글
| SQLD 관리 구문 (0) | 2024.11.16 |
|---|---|
| [SQLD] 1-2 데이터 모델과 SQL (1) | 2024.11.08 |
| [SQLD] 1. 데이터 모델링의 이해 (1) | 2024.11.05 |
| 4. 프로그래밍 언어 활용 (0) | 2024.07.09 |
| 2. 소프트웨어 개발 (0) | 2024.07.04 |