
Caravan analogy (차량 행렬 비유)

차량 10대가 항상 같이 다녀야 하는 상황
비트
ㅡ> 차량 한대
패킷
ㅡ> 차량 10대
ㅡ> 10비트 짜리 패킷
propagation delay
ㅡ> 차량 속도
ㅡ> 시속 100km
trasmission delay
ㅡ> 톨게이트
ㅡ> 차량 한대 지나가는데 12초
딜레이
ㅡ> 톨게이트 12*10 = 120초
ㅡ> 고속도로 100km/100km/h = 1시간
ㅡ> 결론 : 62분
패킷은 청크
ㅡ> 패킷 앞부분이 먼저 빛의속도로 라우터 도달했다고 해서 진행하면 안됨
ㅡ> 뒤엣부분이 도달할 때까지 기다림
ㅡ> 패킷은 한 묶음으로 봐야 함
TCP/IP 네트워크 5계층

app ㅡ> HTTP
transport ㅡ> TCP, UDP
network ㅡ> IP
link ㅡ> WIFI, LTE, 이더넷
physicla layer
하위계층의 기능을 상위계층에서 사용 함
ㅡ> ex) transport의 TCP가 data integrity기능을 app에 제공
데이터 단위

TCP/IP 5계층 모델에서 각 계층의 데이터 단위는 다음과 같습니다:
- 물리 계층 (Physical Layer): 비트
데이터가 전기 신호로 변환되어 전송됩니다. - 데이터 링크 계층 (Data Link Layer): 프레임
비트를 프레임 단위로 묶어 물리적인 주소(MAC 주소)를 통해 전달합니다. - 네트워크 계층 (Network Layer): 패킷, IP데이터그램
프레임을 패킷으로 구성하여 논리적인 주소(IP 주소)를 통해 경로를 설정합니다. - 전송 계층 (Transport Layer): 세그먼트 (TCP의 경우) 또는 데이터그램 (UDP의 경우)
패킷을 세그먼트 또는 데이터그램으로 분할하여 신뢰성 있는 데이터 전송을 지원합니다. - 응용 계층 (Application Layer): 데이터 또는 메시지
최종 사용자에게 전달되는 실제 데이터로, 응용 프로그램 간의 통신을 담당합니다.
데이터그램
ㅡ> 비연결형 전송 방식의 데이터 단위
ㅡ> ex) UDP, IP
ㅡ> 네트워크 계층에서 데이터그램이라 부르는건 IP가 비연결형 전송 방식이기 때문
송신과정
- message → segment → packet → frame → 비트 전송
- 각 계층에서 헤더가 추가되면서 상위 계층의 데이터가 하위 계층으로 전달
- 실제 전송 단계에 이르러 물리적인 비트 단위로 변환되어 네트워크를 통해 전달됩니다.
어플리케이션 계층
어플리케이션
ㅡ> 프로세스
ㅡ> ex.웹브라우저
프로세스 사이에 라우터들이 있는건 무시하고 (∵단순화)
프로세스(웹 브라우저)와 프로세스(서버)간의 통신이라고 생각
왜냐면 네트워크 계층은 네트워크 엣지에만 존재하고
라우터에는 network레이어까지만 존재

클라이언트-서버 구조

서버
ㅡ> ex. 웹 서버
ㅡ> 24시간 열림
ㅡ> 영속적인 ip주소 필요
ㅡ> ip가 고정돼있어야 찾아오지, 매번 바뀌면 못찾아옴
클라이언트
ㅡ> ex. 웹 브라우저
프로세스 연결
한 컴퓨터 (물리적 연결)
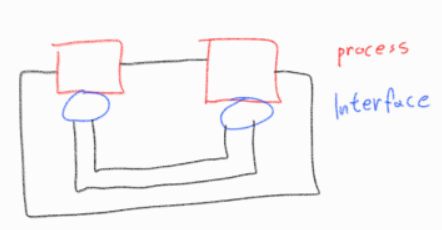
OS에서 inter process comunication(IPC)
ㅡ> 프로세스 사이의 통신을 위해서 os가 인터페이스들을 만들어 놓음
두 컴퓨터 (소켓 통신)


네트워크에서도 똑같은 IPC인데,
프로세스가 각각 다른 컴퓨터에 위치할 뿐이다.
다른 컴퓨터와 프로세스와 통신을 하기 위한 인터페이스를 또 os가 만들어 놨다 (소켓)
근데 소켓이 다른 소켓이랑 통신하려면 일단 주소를 알아야 함
그 주소가 ip adress와 port넘버의 컴비네이션
ip주소
ㅡ> 인터넷에서 어떤 컴퓨터인지의 주소
port
ㅡ> 컴퓨터에서 어떤 프로세스인지의 주소
ㅡ> 프로토콜마다 자주쓰는 포트번호가 있다
ㅡ> http프로토콜은 보통 포트번호 80을 쓴다
네이버 접속
ㅡ> 1.네이버 컴퓨터의 ip주소
ㅡ> 2.네이버 웹 서버 프로세서가 돌고있는 소켓의 port 넘버
ㅡ> 그냥 www.naver.com 치면 dns가 도메인을 ip주소로 변환시켜서 접속시켜 줌
ㅡ> ip주소는 네이버, 다음 각각 다 달라도, port 넘버는 같은거 쓰기로 약속 함
ㅡ> 마치 고려대, 연세대 주소는 달라도, 그 학교의 컴퓨터 네트워크 교수는 401호에 있으라고 약속하는 것
Transport 계층이 App 계층에 제공하는 서비스
1. Data Integrity (데이터 무결성) ㅡ> 데이터 손상x
2. Timing (타이밍, 지연시간) ㅡ> 데이터 전송 딜레이 줄이기
3. Throughput (처리량, 대역폭) ㅡ> 데이터 처리량, 대역폭, 전송 속도
4. Security (보안) ㅡ> 데이터 암호화
유명한 app들이 사용하는 프로토콜

HTTP
ㅡ> HyperText Transfer Protocol

1. HTTP request
2. HTTP respose
이 2가지가 끝임
브라우저에서 하이퍼텍스트 파일 이름으로 요청하면
서버에서 디스크 읽어서 그 하이퍼텍스트 파일 보내줌
TCP를 사용한다
app계층에서 request/response하기 이전에
transport 계층에서 TCP connection을 해줘야 한다
non-persistent HTTP
TCP connection을 사용하고 나면
TCP 연결 끊음
persistent HTTP
TCP connection을 사용한 뒤에도
TCP 연결을 끊지 않고 계속 재사용
HTTP는 persistent를 디폴트로 사용한다
Non-persistent HTTP
유저가 다음 URL에 들어갔다고 가정
ㅡ> www.someSchool.edu/someDepartment/home.index
ㅡ> (10개의 이미지에 대한 레퍼런스와 텍스트를 담고 있음)
ㅡ> 네이버 기사같은거 생각 (텍스트, 이미지)
www.someSchool.edu/someDepartment/home.index
ㅡ> www.someSchool.edu: 학교 웹사이트의 서버(도메인)
ㅡ> /someDepartment: 부서 디렉터리 경로
ㅡ> /home.index: 부서의 홈 페이지 파일
1a. HTTP 클라이언트가 TCP 연결을 시작
1b. HTTP 서버가 TCP 연결을 수락
2. HTTP 클라이언트가 HTTP request 메세지를 전송
3. HTTP 서버가 request를 받고 response 메세지를 전송
4. HTTP 서버가 TCP 연결을 종료
5. HTTP 클라이언트가 reponse 메시지를 받아 HTML을 표시
ㅡ> 브라우저가 HTML(home.index)을 파싱했는데 10개의 JPEG 객체 레퍼런스를 발견
6. 각 JPEG 객체에 대해 1단계부터 5단계까지 반복
User-server state: cookies
HTTP는 'stateless'다.
= 상태가 없다
request가 들어오면,
단순히 response 해주고
더이상 기억x
상대방에 대한 상태 저장x
근데 이게 항상 좋은건 아니다
서버가 날 알아봐주고 뭘 하는게 좋을 수도 있다
그래서 cookie라는 트릭을 사용
처음 웹사이트에 http 요청을 보내면
거기서 나에게 고유ID를 부여해서 응답한다
이 고유ID가 쿠키고, 클라이언트가 그 번호를 저장해둔다
웹서버는 백엔드 데이터베이스에 그 ID에 해당하는 영역을 만들어 정보를 저장한다
웹 브라우저에서 관리하는 디렉토리를 보면
각 웹사이트에서 나(client)에게 부여한 일련번호가 있다 (쿠키)
http 리퀘스트를 할 때, 이 쿠키 일련번호를 포함해서 보내면
웹 서버는, 백엔드 데이터베이스에서 그 일련번호에 해당하는 데이터를 이용해 사용자에게 맞춤 응답을 한다
Web caches (proxy server)

목표(goal): 클라이언트 요청을 원본 서버(origin server)를 거치지 않고 처리하는 것.
작동 과정:
- 사용자가 브라우저를 설정하면, 웹 액세스가 캐시를 통해 이루어집니다.
- 브라우저는 모든 HTTP 요청을 캐시에 전송합니다.
- 캐시에 객체(데이터)가 있으면, 캐시가 해당 객체를 반환합니다.
- 캐시에 객체가 없으면, 캐시가 원본 서버에 객체를 요청하여 가져온 뒤, 이를 클라이언트에 반환합니다.
요약: 웹 캐시(프록시 서버)는 원본 서버에 부하를 줄이고 빠르게 요청을 처리하기 위해, 클라이언트가 자주 요청하는 데이터를 저장해두고, 요청 시 캐시에서 직접 반환하는 역할을 합니다.
<장점>
외부로 나가는 트래픽이 줄어들어서
AS가 상위 AS에게 내야되는 비용이 줄어든다
예) 한양대가 KT에게 지불하는 돈이 줄어듬
<단점>
이건 캐쉬의 단점인데
최신성 문제 : 원본 서버의 내용이 업데이트 됐는데 캐시 서버는 이전의 내용
일관성 문제 : 여러 client가 캐시서버를 각각 다른날짜에 사용했는데, 각각 최신화가 다르게 돼있으면 일관성 깨짐
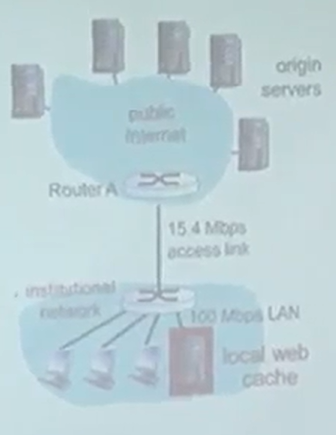
Caching example

가정 (Assumptions)
- 평균 객체 크기: 1M 비트
- 브라우저에서 원본 서버로의 평균 요청 속도: 초당 15회 요청
- 브라우저로의 평균 데이터 전송 속도: 15 Mbps
- 라우터 A에서 원본 서버까지의 RTT(왕복 시간): 2초 (인터넷 지연 시간)
- 접속 링크 속도: 15.4 Mbps
결과 (Consequences)
- LAN 활용률: 15%
- 접속 링크 활용률: 99%
- 총 지연 시간:
- total delay = internet delay + access delay + LAN delay
- = 2초 + 몇 분 + 몇 밀리초
ㅡ> 캐시가 없을 때의 병목 현상
ㅡ> 평균이 15면 15가 넘을때도 있다는 것
ㅡ> access link가 99%로 포화상태인 반면, LAN 활용률은 상대적으로 낮음
직관적 해결책 : 케이블 확장공사를 한다
(S1) 더 빠른 접속 링크(faster access link)
ㅡ> 케이블 확장공사를 한
ㅡ> 단점 : 공사 비용이 많이 든다

해결 방안 (Possible solution)
- 접속 링크 대역폭을 증가: 기존 15.4 Mbps에서 154 Mbps로 접속 링크 대역폭을 늘려 데이터 전송 용량을 높입니다.
결과 (Consequences)
- LAN 활용률: 여전히 15%로 유지됩니다.
- 접속 링크 활용률: 기존 99%에서 9.9%로 감소합니다.
- 총 지연 시간:
- total delay = internet delay + access delay + LAN delay
- = 2초 + 몇 밀리초 + 몇 밀리초
(S2) 로컬 캐시 설치(install local cache)
ㅡ> 비용도 덜들고, 성능도 더 좋음
ㅡ> 케이블 확장공사해도 2초를 넘지만, 캐시 서버를 두면 1.4초정도
캐시 설치 (Install Cache)
- 가정: 캐시 히트율(hit rate)이 0.4, 즉 40%의 요청이 캐시에서 직접 처리됩니다.
결과 (Consequences)
- 40%의 요청이 거의 즉시 처리됨: 캐시에서 데이터를 제공하므로 지연이 거의 없으며, 빠르게 응답할 수 있습니다.
- 60%의 요청은 원본 서버에서 처리됨: 캐시에 없는 데이터는 여전히 원본 서버에서 가져와야 합니다.
- 접속 링크 사용률 감소: 접속 링크의 사용률이 60%로 줄어들어, 지연 시간이 10 밀리초 정도로 매우 낮아집니다.
- 평균 총 지연 시간 계산:
- total avg delay = internet delay + access delay + LAN delay
- 60%의 요청은 원본 서버에서 처리되며, 평균 지연 시간은 0.6×2.01초가 됩니다.
- 40%의 요청은 캐시에서 처리되어 거의 지연이 없으므로 0.4 밀리초로 계산됩니다.
- 결과적으로 평균 지연 시간은 1.4초 미만으로 줄어듭니다.
- 비용 효율성: 154 Mbps 링크를 설치하는 것보다 로컬 캐시 설치가 더 비용 효율적이며, 성능 또한 향상됩니다.
Conditional GET
ㅡ> 캐시의 일관성문제를 '어느정도' 해결
ㅡ> 조건에 따라 GET을 하겠다
ㅡ> 조건 : 수정 날짜
ㅡ> 프록시 서버가 주기적으로 최신버전인지 확인
목표 (Goal)
- 캐시에 최신 버전의 객체가 있는 경우 서버로부터 해당 객체를 다시 전송받지 않는 것.
- 이를 통해:
- 객체 전송 지연이 줄어듭니다.
- 네트워크 링크의 사용량이 감소합니다.
동작 원리
- 캐시:
- 캐시된 사본의 날짜를 If-Modified-Since 헤더에 포함하여 HTTP 요청을 보냅니다.
- 예: If-Modified-Since: <date>
- 서버:
- 서버는 요청된 객체가 지정된 날짜 이후에 수정되지 않은 경우, HTTP 304 Not Modified 응답을 반환합니다. 이 경우 객체 데이터는 전송되지 않습니다.
- 반대로, 객체가 수정된 경우 HTTP 200 OK 응답과 함께 최신 데이터를 포함하여 전송합니다.

예시
- 첫 번째 시나리오: 클라이언트가 If-Modified-Since 헤더를 포함해 요청을 보내고, 서버는 해당 날짜 이후에 객체가 수정되지 않았음을 확인하고, HTTP 304 Not Modified 응답을 보냅니다.
- 두 번째 시나리오: 서버가 요청된 객체가 수정되었음을 확인하면, HTTP 200 OK 응답과 함께 업데이트된 데이터를 전송합니다.
DNS (domain name system)
IP주소는 사람이 쓰기 불편해서
이름을 쓴다
DNS가 이름을 IP주소로 바꿔준다
마치 전화번호부와 같다
친구 이름만 알고 전화번호를 모를때
전화번호부에서 번호를 찾는 것
- DNS의 목적
- IP 주소와 도메인 이름 간의 매핑(변환)을 수행하는 시스템입니다.
- 예를 들어, 사람이 www.yahoo.com을 입력하면, DNS는 이를 해당 IP 주소로 변환해 서버에 연결할 수 있게 합니다.
- DNS의 특징
- 분산 데이터베이스 (Distributed Database): 많은 이름 서버가 계층 구조로 구현되어 있습니다.
- 응용 계층 프로토콜 (Application-Layer Protocol): 호스트와 이름 서버가 상호 통신하여 도메인 이름을 IP 주소로 변환합니다.
- 추가 정보
- 인터넷의 핵심 기능으로, 응용 계층 프로토콜로 구현되었습니다.
- 네트워크의 "엣지"에서 복잡성이 존재합니다.
데이터베이스를 하나에 몰아넣으면
검색시간이 어마어마하고
거리가 먼 곳에선 통신이 한참걸린다
그리고 그 하나의 데이터베이스가 망가지면 다같이 망한다
ㅡ> 데이터베이스를 분산화, 계층화
DNS의 분산 및 계층적 구조

DNS의 계층적 구조
- Root DNS Servers: DNS 계층 구조의 최상위에 위치하며, .com, .org, .edu와 같은 최상위 도메인(TLD) 서버를 관리합니다.
- TLD DNS Servers: 각 최상위 도메인별 서버로, 예를 들어 .com 도메인 서버는 yahoo.com, amazon.com 같은 하위 도메인 DNS 서버로 연결됩니다.
- 하위 도메인 DNS Servers: 특정 도메인(예: amazon.com)에 대한 최종 IP 주소 정보를 제공합니다.
예시: www.amazon.com의 IP 주소를 찾는 과정
- 클라이언트가 루트 DNS 서버에 질의하여 com TLD DNS 서버를 찾습니다.
- .com DNS 서버에 질의하여 amazon.com에 대한 DNS 서버를 찾습니다.
- amazon.com DNS 서버에 질의하여 최종적으로 www.amazon.com의 IP 주소를 얻습니다.
DNS의 루트 네임 서버(Root Name Servers)
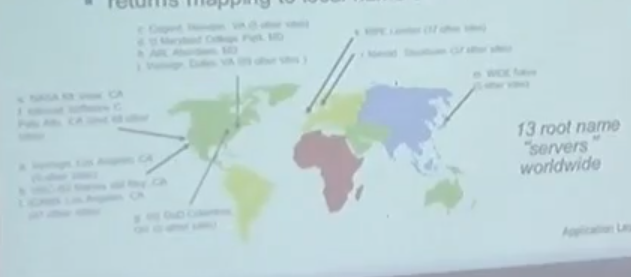
루트 네임 서버의 역할
- 로컬 네임 서버로부터 요청을 받음: 로컬 네임 서버가 도메인 이름을 해석할 수 없을 때, 루트 네임 서버에 요청을 보냅니다.
- 권한이 있는 네임 서버(Authoritative Name Server)에 연결: 루트 네임 서버는 해당 도메인에 대한 정보를 알지 못할 경우, 해당 도메인에 대한 권한이 있는 네임 서버에 연결합니다.
- 매핑 정보 수신 및 반환: 권한이 있는 네임 서버에서 해당 도메인 이름과 IP 주소의 매핑 정보를 받아, 이를 로컬 네임 서버에 전달합니다.
전 세계 루트 네임 서버의 분포
- 전 세계적으로 13개의 주요 루트 네임 서버가 운영되고 있으며, 이들은 다양한 위치에 분산되어 있습니다.
- 각 루트 네임 서버는 전 세계 사용자들에게 빠르고 안정적인 DNS 서비스를 제공하기 위해 여러 물리적 서버로 구성된 클러스터로 운영됩니다.
TLD 서버, 권한 있는 DNS 서버
TLD 서버 (Top-Level Domain Servers)
- 역할: .com, .org, .net, .edu, .aero, .jobs, .museum과 같은 일반 최상위 도메인(gTLD) 및 국가 코드 최상위 도메인(ccTLD) (예: .uk, .fr, .ca, .jp)에 대한 정보를 관리합니다.
- 관리자:
- Network Solutions는 .com TLD 서버를 관리합니다.
- Educause는 .edu TLD 서버를 관리합니다.
TLD 서버는 루트 네임 서버 바로 아래에 위치하며, 각 도메인의 하위 DNS 서버 정보를 제공합니다.
권한 있는 DNS 서버 (Authoritative DNS Servers)
- 역할: 조직의 도메인에 대한 최종적인 이름과 IP 주소의 매핑 정보를 제공합니다. 예를 들어, example.com 도메인에 대한 IP 주소를 보유하고 있으며, 이 도메인에 대한 모든 요청을 처리할 수 있는 권한을 가집니다.
- 유지 관리: 이 서버는 조직 자체 또는 외부 서비스 제공자가 관리할 수 있습니다.
로컬 DNS 네임 서버(Local DNS Name Server)
- DNS 계층 구조에 엄격하게 속하지 않음
- 로컬 DNS 서버는 공식적인 DNS 계층 구조의 일부는 아니지만, DNS 요청을 처리하는 데 중요한 역할을 합니다.
- ISP, 회사, 대학 등에서 사용
- 각 ISP(가정용, 기업용, 학교용)에는 기본적으로 하나의 로컬 DNS 서버가 있으며, 이를 **기본 네임 서버(default name server)**라고도 부릅니다.
- DNS 요청 처리
- 호스트(사용자 컴퓨터)가 DNS 쿼리를 생성하면, 이 쿼리는 로컬 DNS 서버로 전송됩니다.
- 로컬 DNS 서버에는 최근에 요청된 이름-주소 변환 쌍이 캐시에 저장되어 있으며, 이를 통해 빠른 응답이 가능하지만, 캐시가 최신이 아닐 수 있습니다.
- 로컬 DNS 서버는 프록시 역할을 하여 요청을 상위 DNS 계층에 전달합니다.
DNS 이름 해석 예시

과정 설명 (Iterated Query 방식)
- 클라이언트 요청: cis.poly.edu의 호스트가 gaia.cs.umass.edu의 IP 주소를 요청하며, 로컬 DNS 서버(dns.poly.edu)에 쿼리를 보냅니다.
- 루트 DNS 서버로 쿼리 전송: 로컬 DNS 서버가 루트 DNS 서버에 gaia.cs.umass.edu에 대한 정보가 있는지 요청합니다.
- 루트 DNS 서버 응답: 루트 DNS 서버는 edu 도메인에 대해 알고 있으므로, .edu TLD DNS 서버의 정보를 로컬 DNS 서버에 전달합니다.
- TLD DNS 서버로 쿼리 전송: 로컬 DNS 서버는 이제 TLD DNS 서버 (.edu)에 쿼리를 보냅니다.
- TLD DNS 서버 응답: TLD DNS 서버는 umass.edu 도메인에 대한 권한 있는 DNS 서버의 위치를 알려줍니다.
- 권한 있는 DNS 서버로 쿼리 전송: 로컬 DNS 서버는 cs.umass.edu 도메인에 대한 권한 있는 DNS 서버에 최종 쿼리를 보냅니다.
- 최종 응답 수신: 권한 있는 DNS 서버는 gaia.cs.umass.edu의 IP 주소를 반환합니다.
- 클라이언트에 응답 전달: 로컬 DNS 서버가 해당 IP 주소를 클라이언트(cis.poly.edu의 호스트)에게 전달합니다.
요약
이 예시는 **반복적 쿼리(iterated query)**를 통해, 각 단계에서 DNS 서버가 "내가 알지 못하지만 이 서버에 물어보라"며 다음 서버를 안내하고, 최종적으로 IP 주소를 얻는 과정을 보여줍니다.
DNS 레코드(DNS Records)
DNS는 리소스 레코드(RR)라는 형식으로 데이터를 저장하는 분산 데이터베이스입니다.
리소스 레코드 형식 (RR format)

- 형식: (name, value, type, ttl)
- 각 레코드는 이름(name), 값(value), 유형(type), 유효 시간(ttl)으로 구성됩니다.
주요 DNS 레코드 유형
- Type = A (Address Record)
- name: 호스트 이름 (예: www.example.com)
- value: IP 주소
- 역할: 특정 호스트 이름을 IP 주소로 매핑하는 데 사용됩니다.
- Type = NS (Name Server Record)
- name: 도메인 이름 (예: example.com)
- value: 이 도메인에 대한 권한 있는 네임 서버의 호스트 이름
- 역할: 해당 도메인의 권한 있는 DNS 서버를 지정합니다.
- Type = CNAME (Canonical Name Record)
- name: 별칭 이름 (alias name)
- value: 정식 이름(실제 이름, canonical name)
- 역할: 별칭을 정식 이름으로 매핑하여, 여러 이름이 동일한 IP 주소를 가리킬 수 있도록 합니다. 예를 들어, www.ibm.com은 실제로 servereast.backup2.ibm.com일 수 있습니다.
- Type = MX (Mail Exchange Record)
- name: 도메인 이름
- value: 메일 서버의 이름
- 역할: 도메인에 대한 메일 서버를 지정하여 이메일 전송을 처리합니다.
'CS > 네트워크' 카테고리의 다른 글
| 전송계층2 - TCP, segment구조, RTT, 타임아웃 (0) | 2024.09.20 |
|---|---|
| 전송계층 1 - RDT효율 : Go-Back-N, Seletive Repeat (0) | 2024.09.20 |
| 2. 어플리케이션 계층2 (0) | 2024.09.15 |
| 2. 어플리케이션 계층 (0) | 2024.09.09 |
| 컴퓨터 네트워크 기본1 (0) | 2024.08.28 |